
RPAの入門として、Power Automate Desktopの使い方を紹介していきます。今回は、Webサイトからブログ記事の見出し情報(構造化データ)を取得して、CSVファイルに出力する処理を自動化したいと思います。
【初心者歓迎・RPA個人講座】RPAを一から学ぶITスクール
Power Automate Desktopのフロー構築
【Step.1】Webブラウザの起動
Webブラウザを起動して、こちらの練習用のWebサイトにアクセスします。ブラウザはこのまま開いておきます。
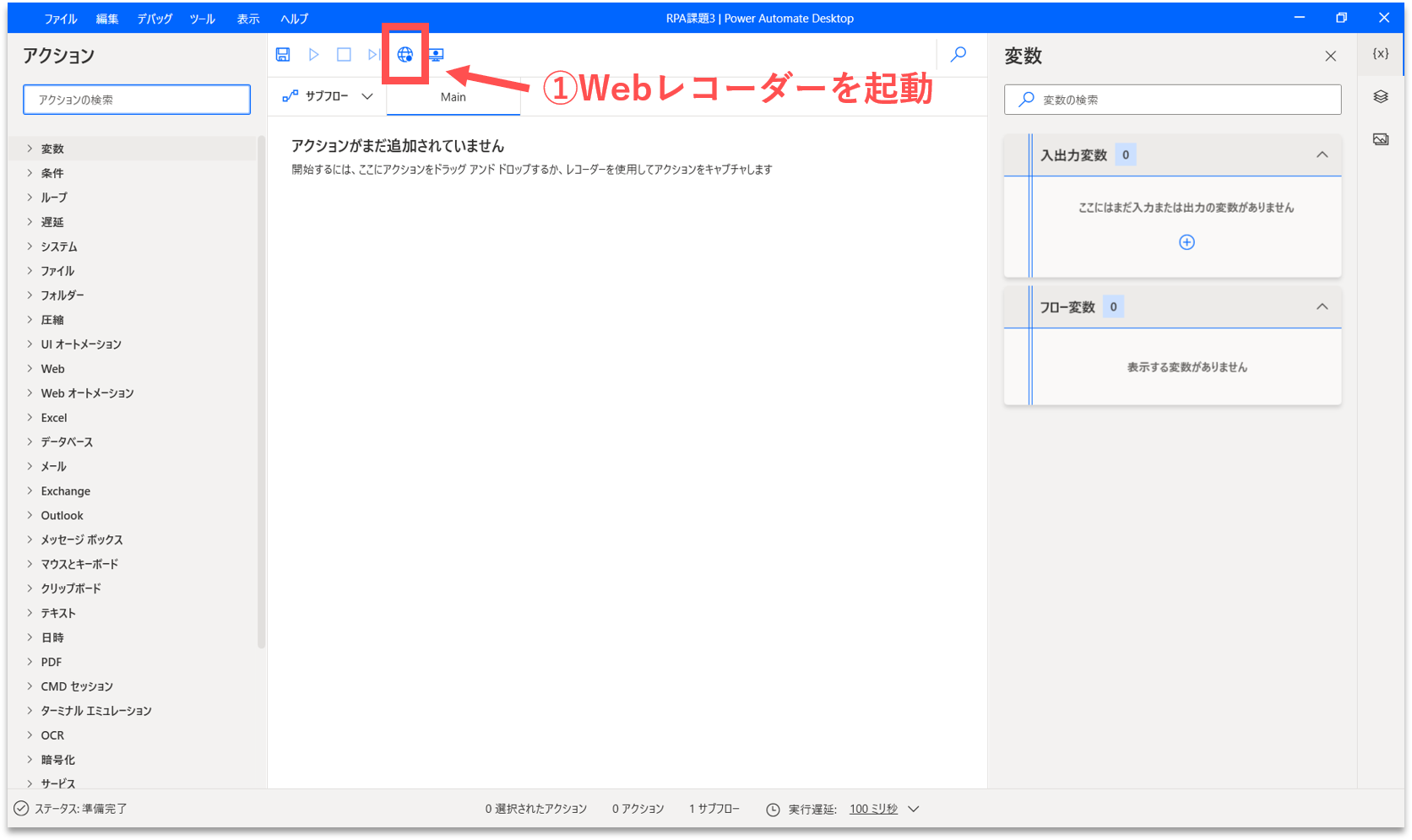
【Step.2】Webレコーダーの起動
Webブラウザの操作を自動記録させるために、Webレコーダーを起動させます。上部の「Webレコーダー」アイコンをクリックします。
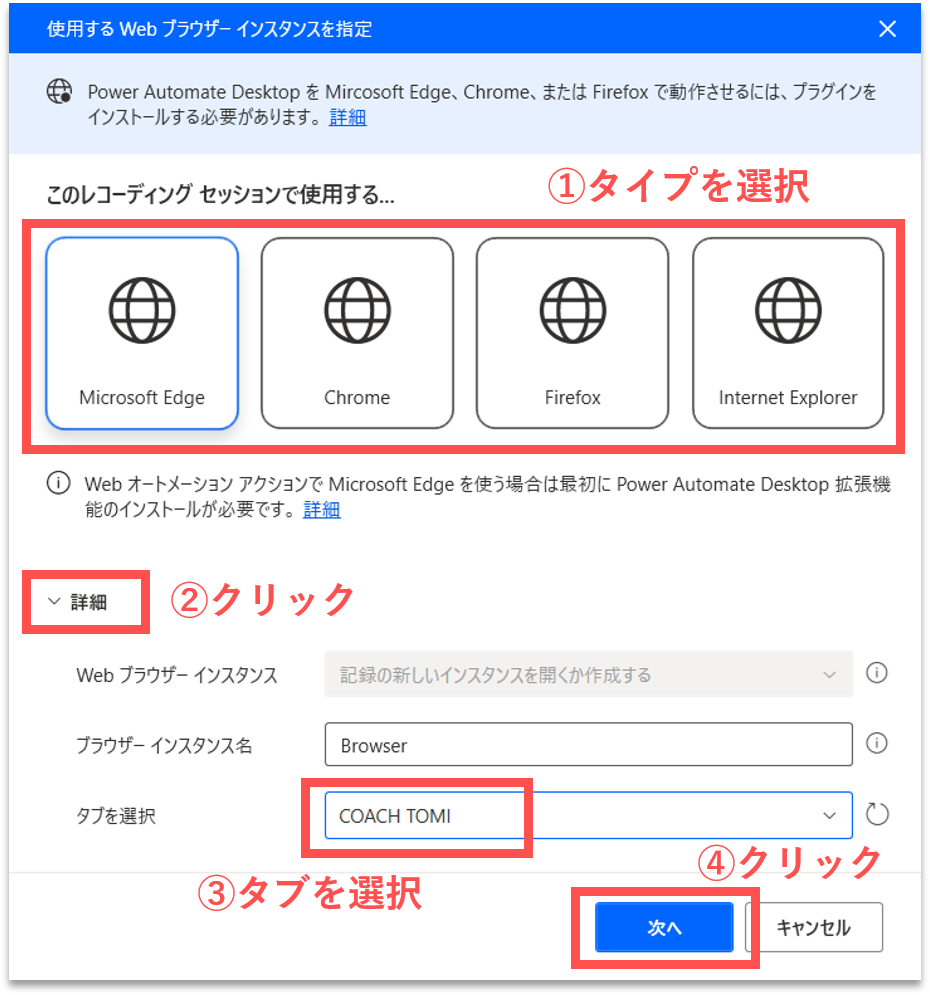
パネルが起動します。ブラウザのタイプを指定して、「詳細」エリアを開きます。「タブを選択」で、【Step.1】で開いた練習用のWebサイトを選択します。そして、「次へ」ボタンをクリックします。
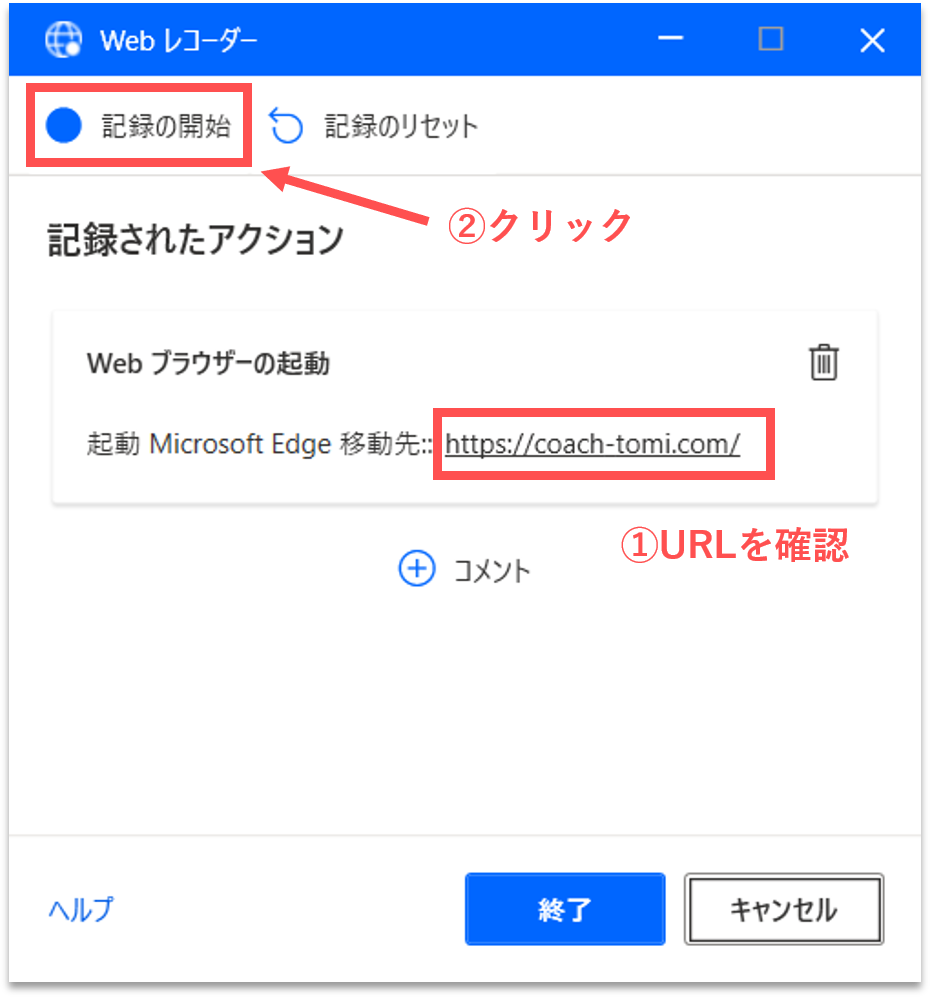
【Step.3】Webレコーダーの記録開始
「Webレコーダー」パネルが起動します。一番初めに開くWebサイトのURLが設定されていることが確認できます。ここから、Webブラウザの操作を自動記録していきます。操作内容がそのまま記録されるので慎重に実行してください。では、「記録の開始」をクリックします。
先ずは、ヘッダーメニューの「ブログ」にカーソルを合わせてクリックします。ブログ記事の一覧画面に遷移します。
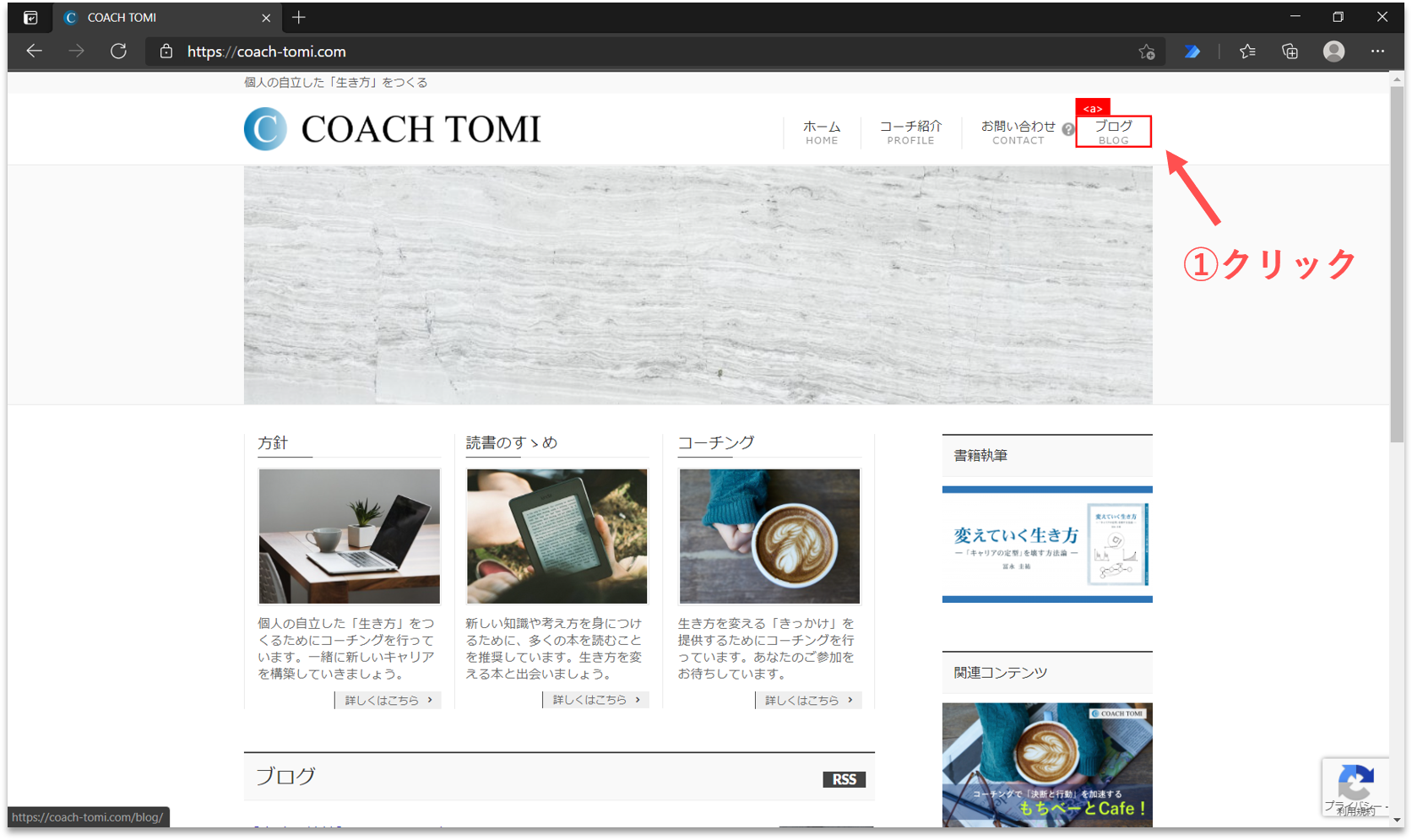
【Step. 4】Webレコーダーの記録終了
ブラウザ上に表示された構造化データを取得するために、一度Webレコーダーを終了させます。「Webレコーダー」パネルの「記録の一時停止」をクリックしてから、「終了」ボタンをクリックします。
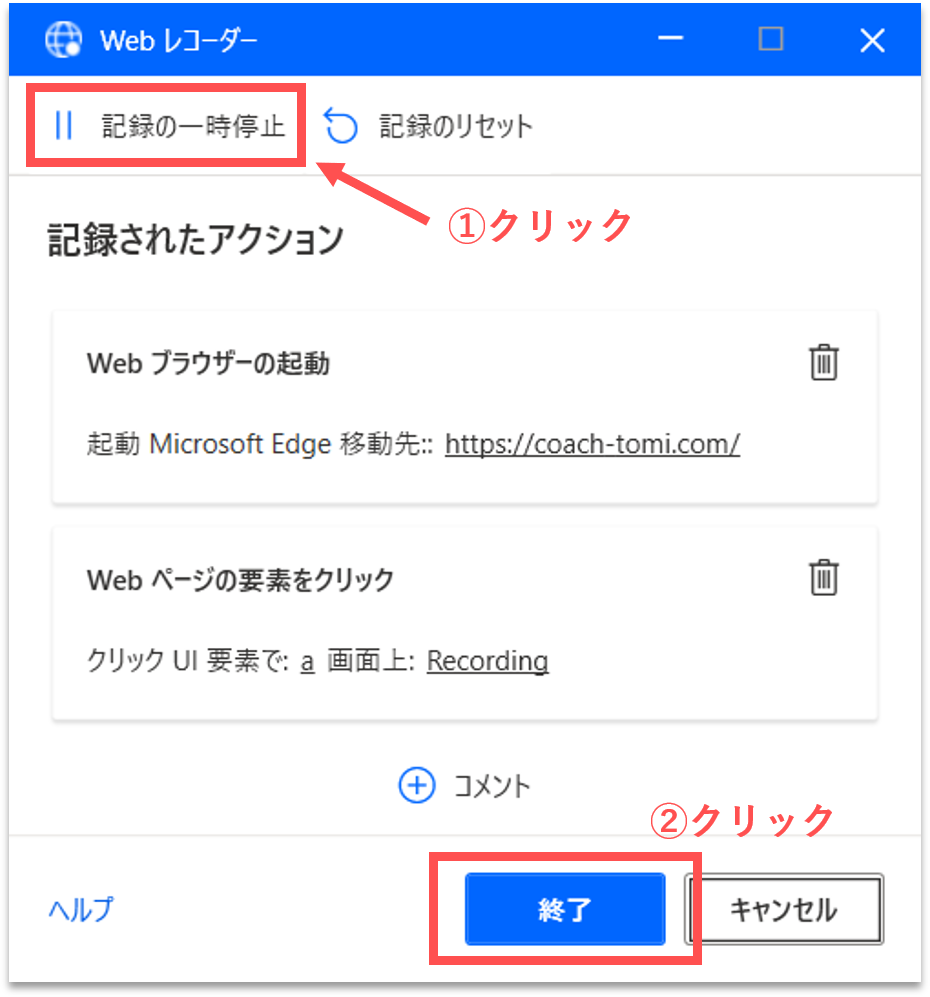
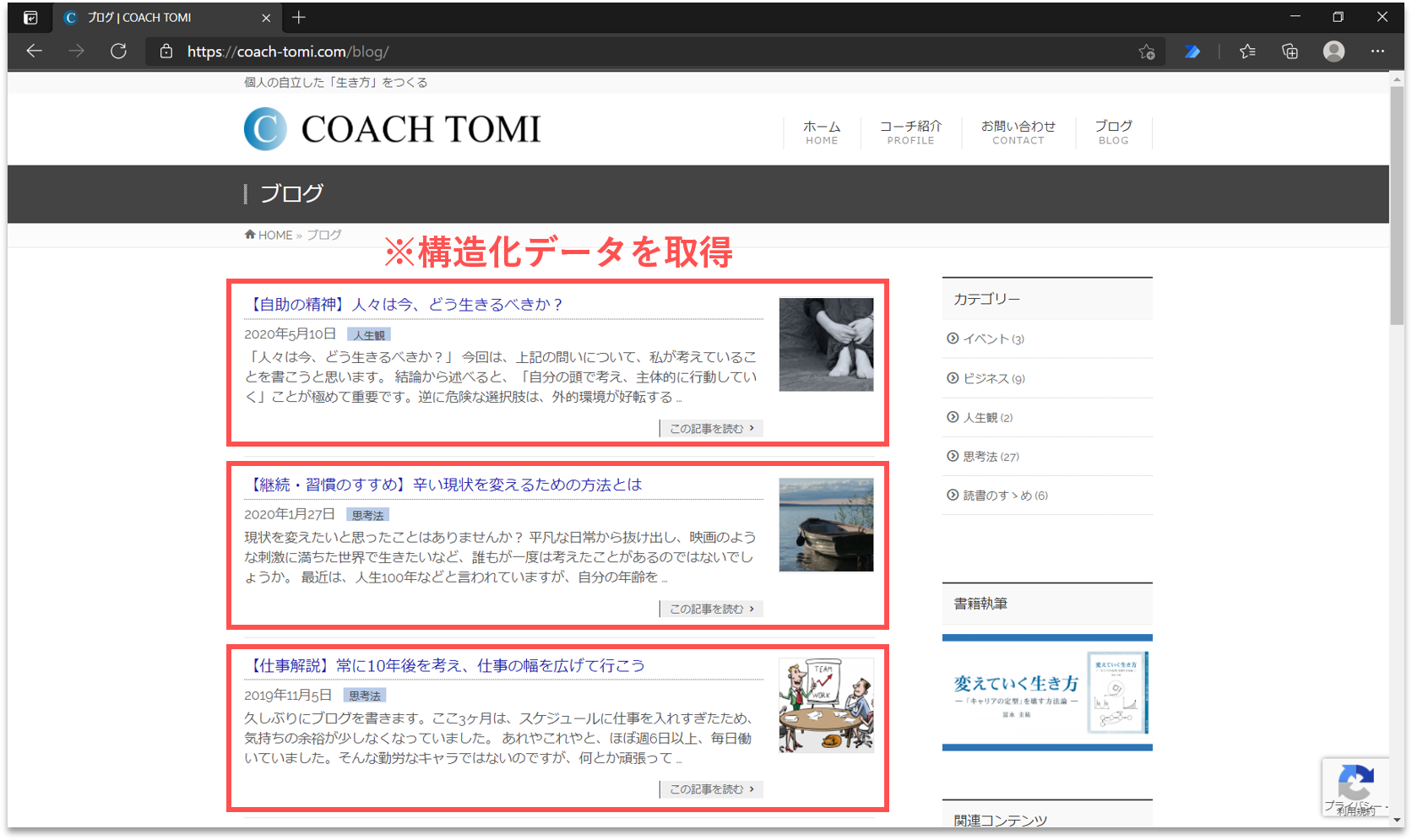
【Step. 5】構造化データの取得
今回は、ブログ記事の見出し情報(構造化データ)の中から、「作成日」、「カテゴリ」、「題名」、「URL」の4項目を取得したいと思います。取得するページの最大数は3とします。
画面左側のアクション検索窓に「抽出」と入力します。「Webページからデータを抽出する」アクションを、フロー内の「Webページのリンクをクリックします」アクションの直下にドラッグ&ドロップします。
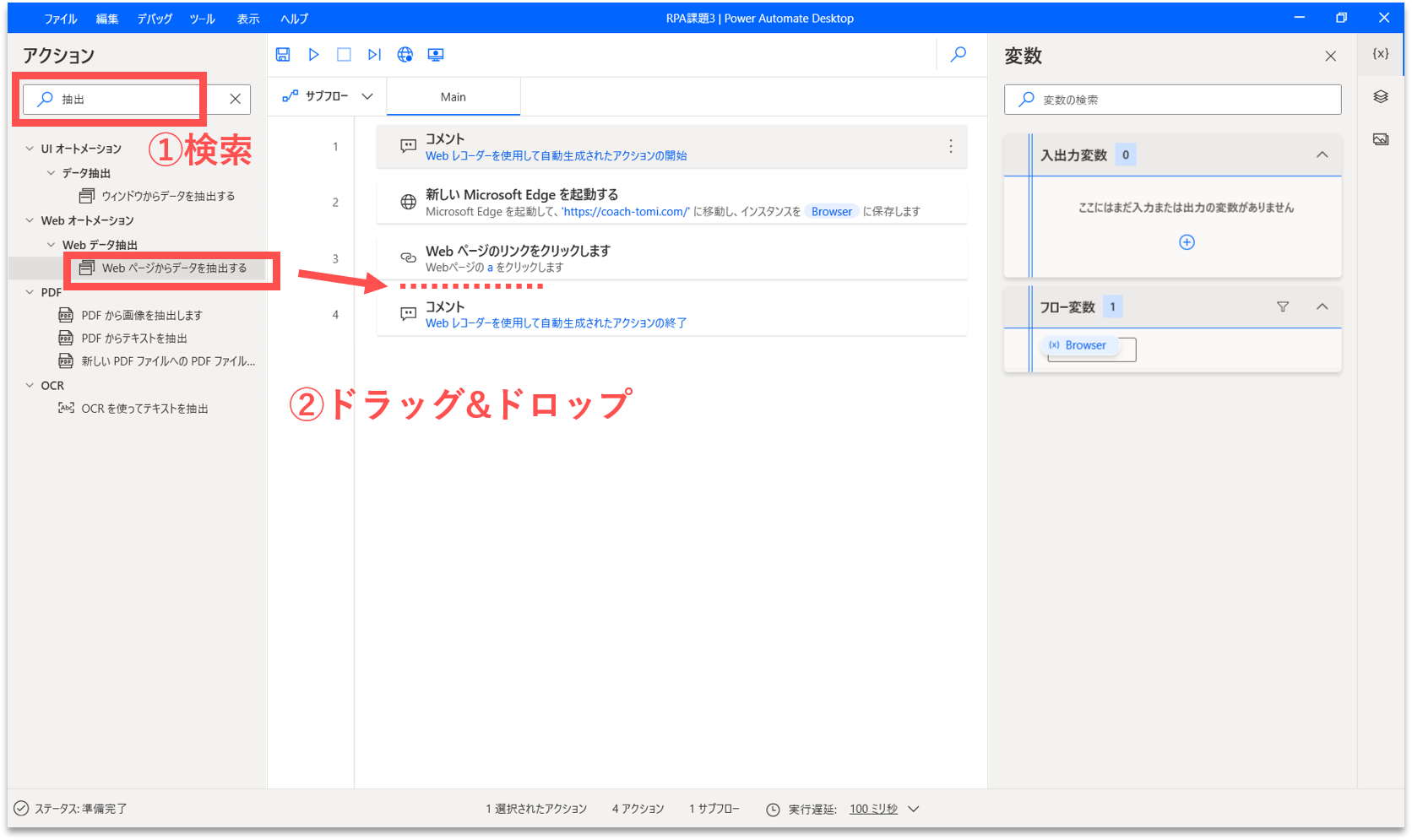
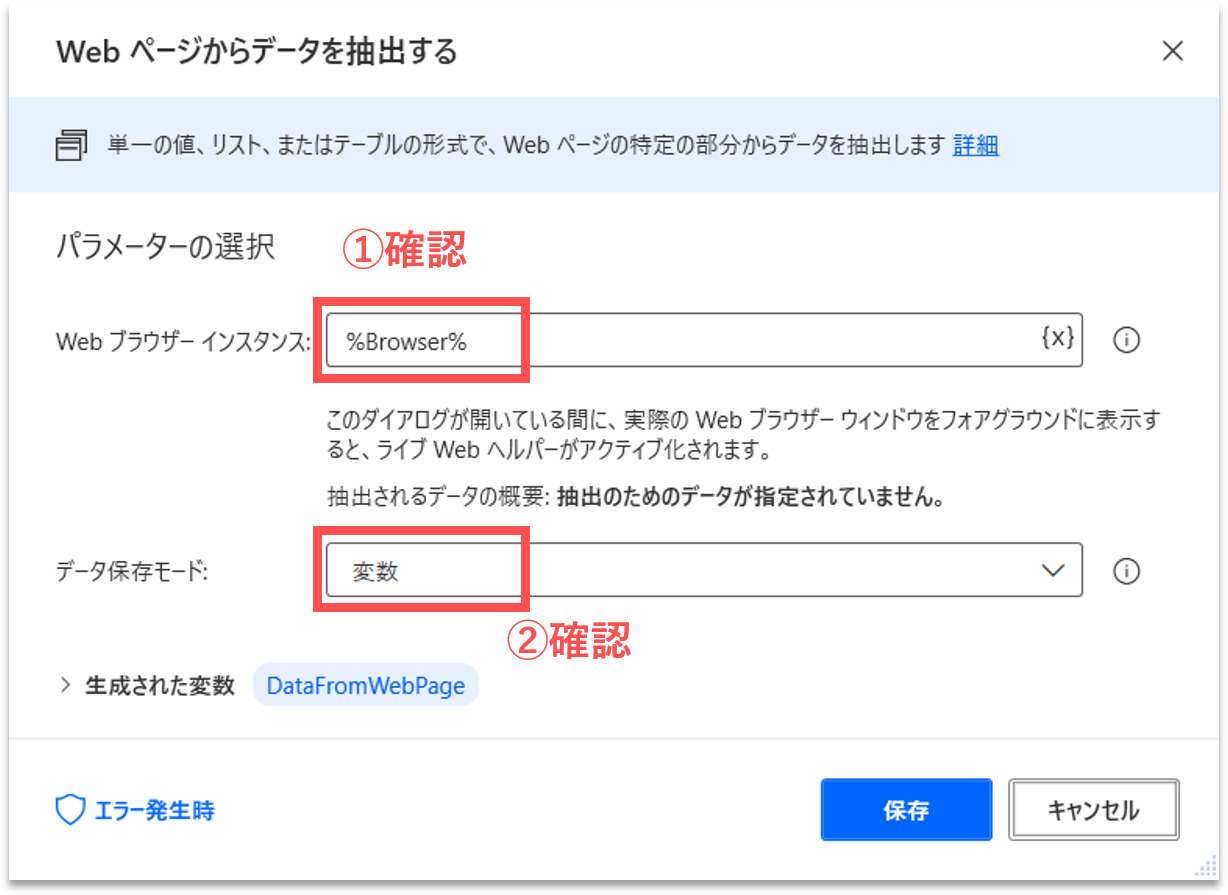
すると、プロパティ設定の画面が開きます。「Webブラウザインスタンス」には「%Browser%」が、「データ保存モード」には「変数」が設定されていることを確認します。「%Browser%」は、最初に開いたWebブラウザのインスタンス名です。「データ保存モード」は取得した構造化データの保存先です。一旦、変数に保存することにします。他には、Excelスプレッドシートに直接保存することもできるようです。
【Step.6】作成日の取得
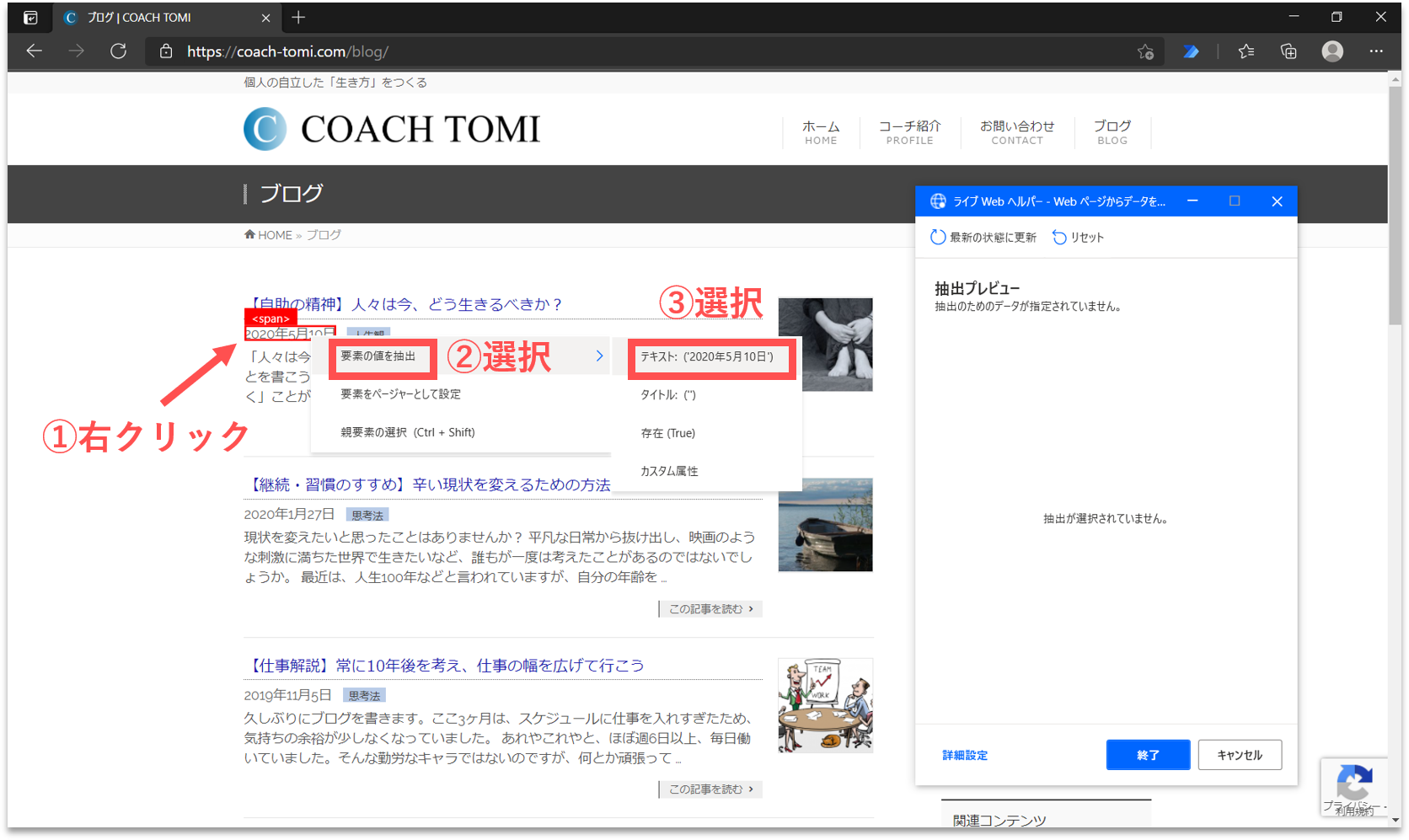
このプロパティ設定の画面が開いた状態で、Webブラウザ画面に表示を切り替えると、「ライブWebヘルパー」と呼ばれるパネルが出現します。先ずは、ブログ記事の「作成日」を取得します。画面内の一番目に表示されたブログ記事の作成日にカーソルを合わせて右クリックします。そして、「要素の値を抽出」を選択し、一覧の中から「テキスト:(’・・・’)」をクリックします。
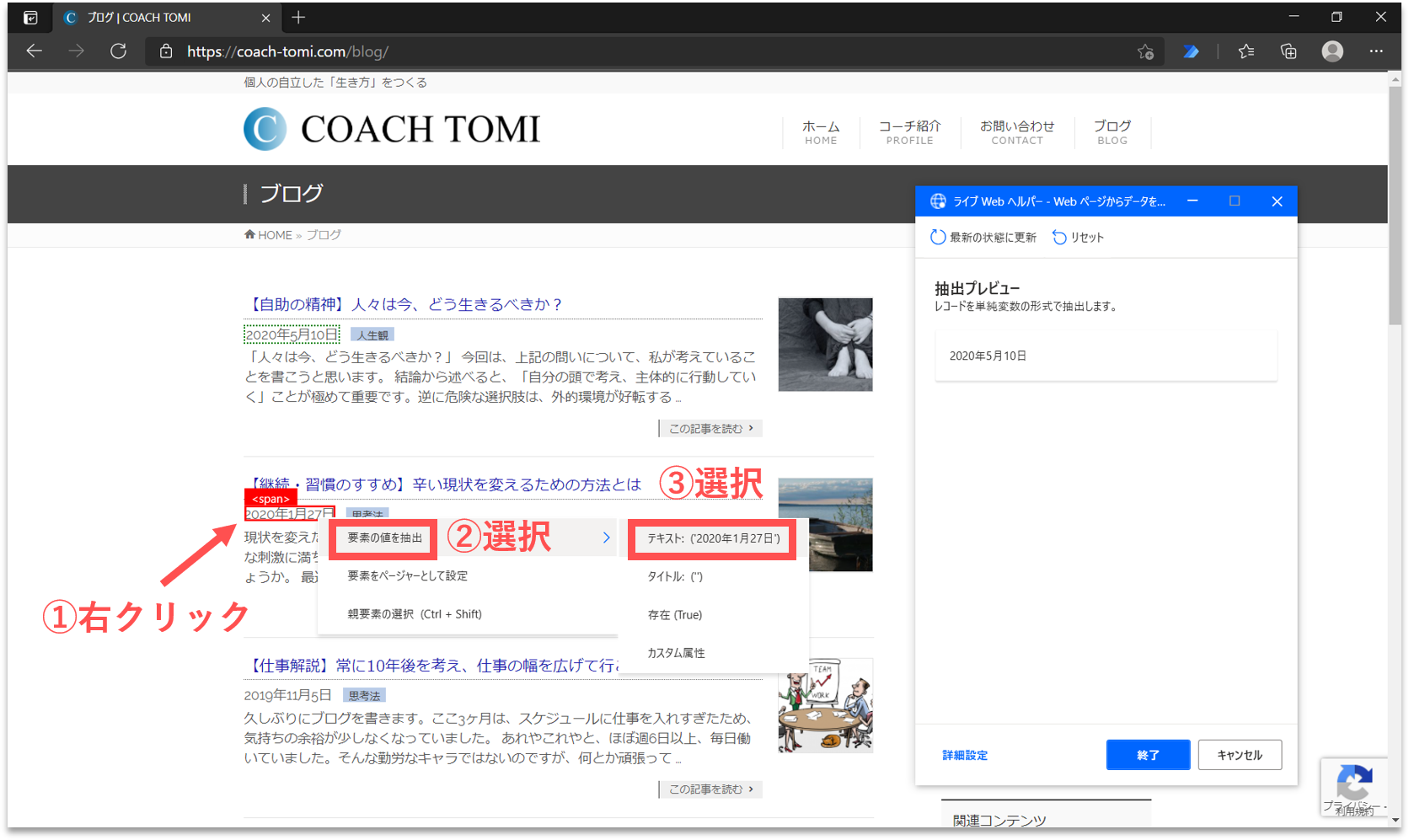
続けて、二番目に表示されたブログ記事の作成日にカーソルを合わせて右クリックします。そして、「要素の値を抽出」を選択し、一覧の中から「テキスト:(’・・・’)」をクリックします。(※なお、ここでは一番目と二番目の作成日を順に指定することで、ページ内のデータ構造を自動認識させています。)
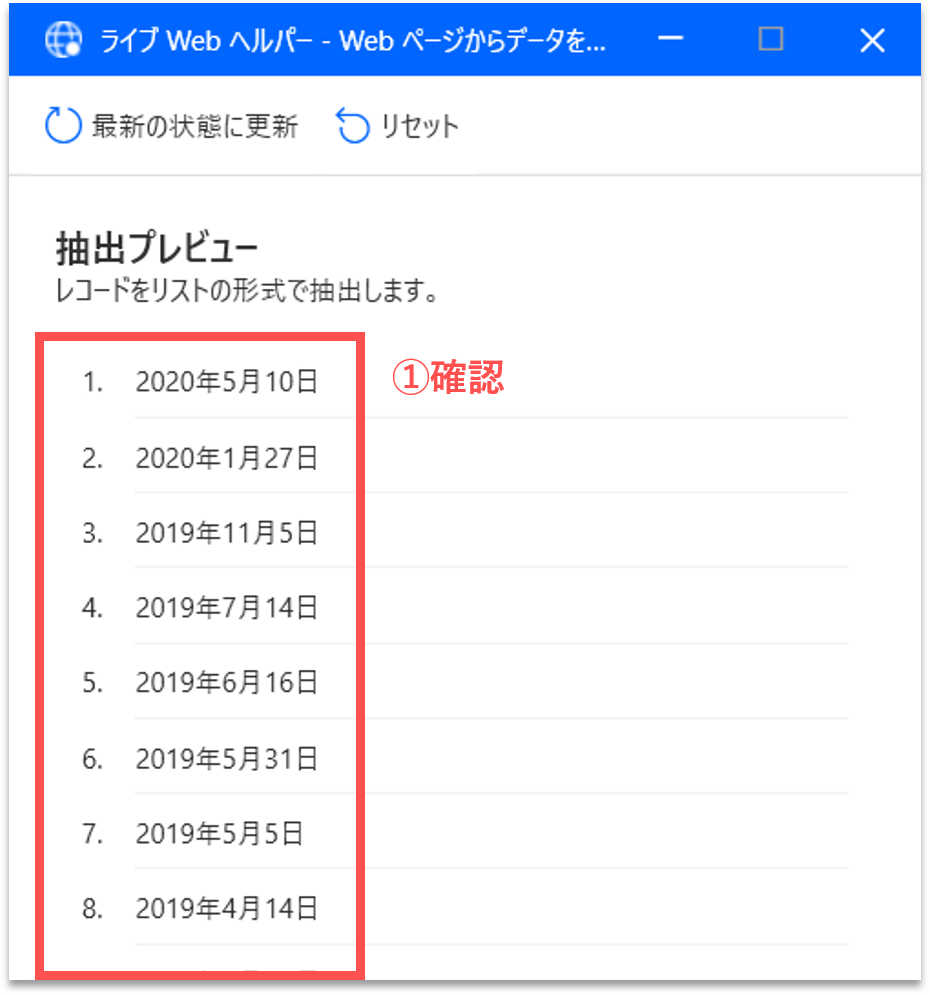
すると、「ライブWebヘルパー」パネルに、取得する構造化データのプレビューが表示されます。各ブログ記事の作成日のリストが表示されていることが確認できます。
【Step.7】カテゴリの取得
続けて、ブログ記事の「カテゴリ」を取得します。画面内の一番目に表示されたブログ記事のカテゴリにカーソルを合わせて右クリックします。そして、「要素の値を抽出」を選択し、一覧の中から「テキスト:(’・・・’)」をクリックします。
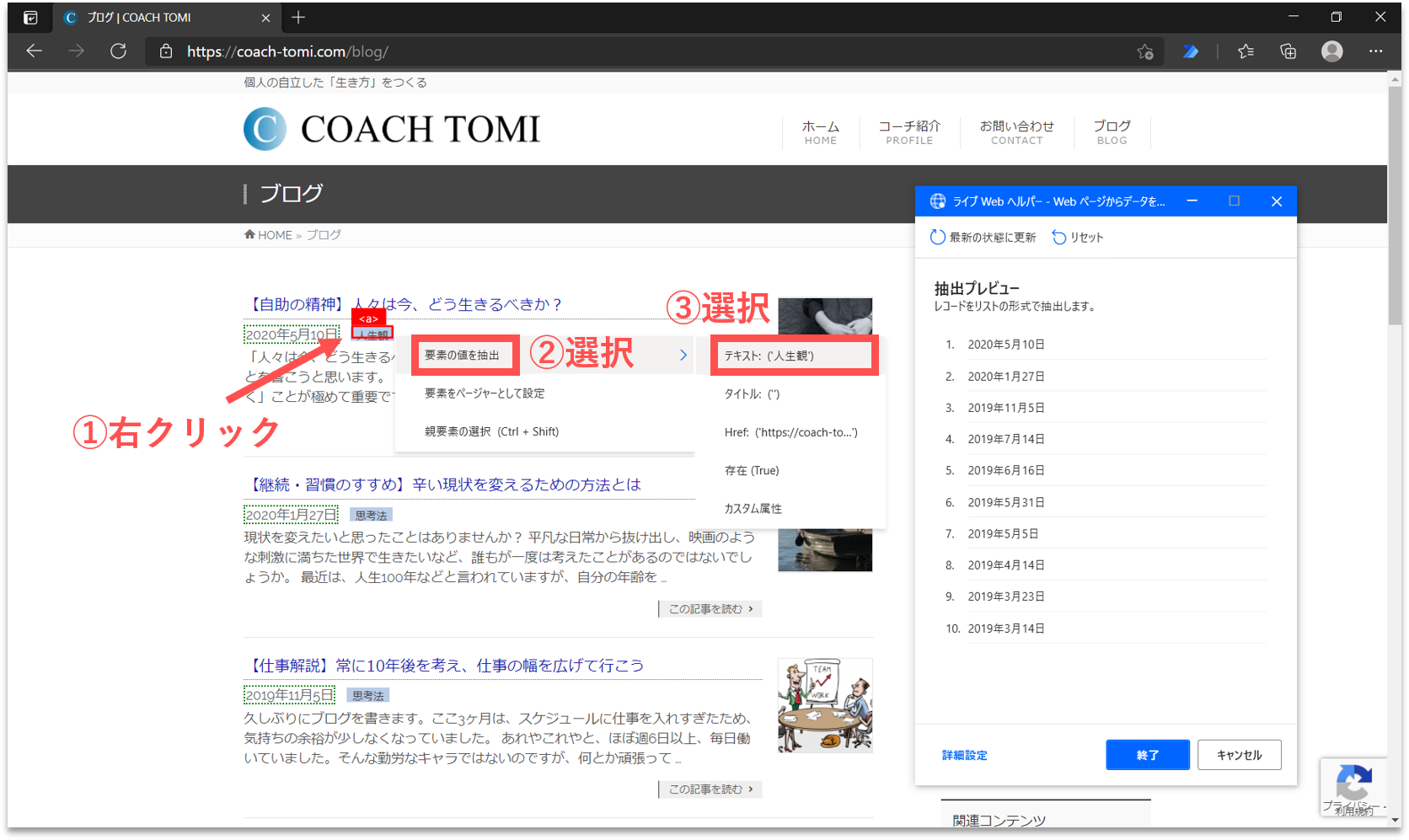
すると、「ライブWebヘルパー」パネルに、取得する構造化データのプレビューが表示されます。右端の列にカテゴリのリストが追加されていることが確認できます。(※なお、【Step.6】の作成日にて、ページ内のデータ構造を既に自動認識させているので、カテゴリは一番目のみの指定で済みます。以下、同様です。)
【Step.8】題名の取得
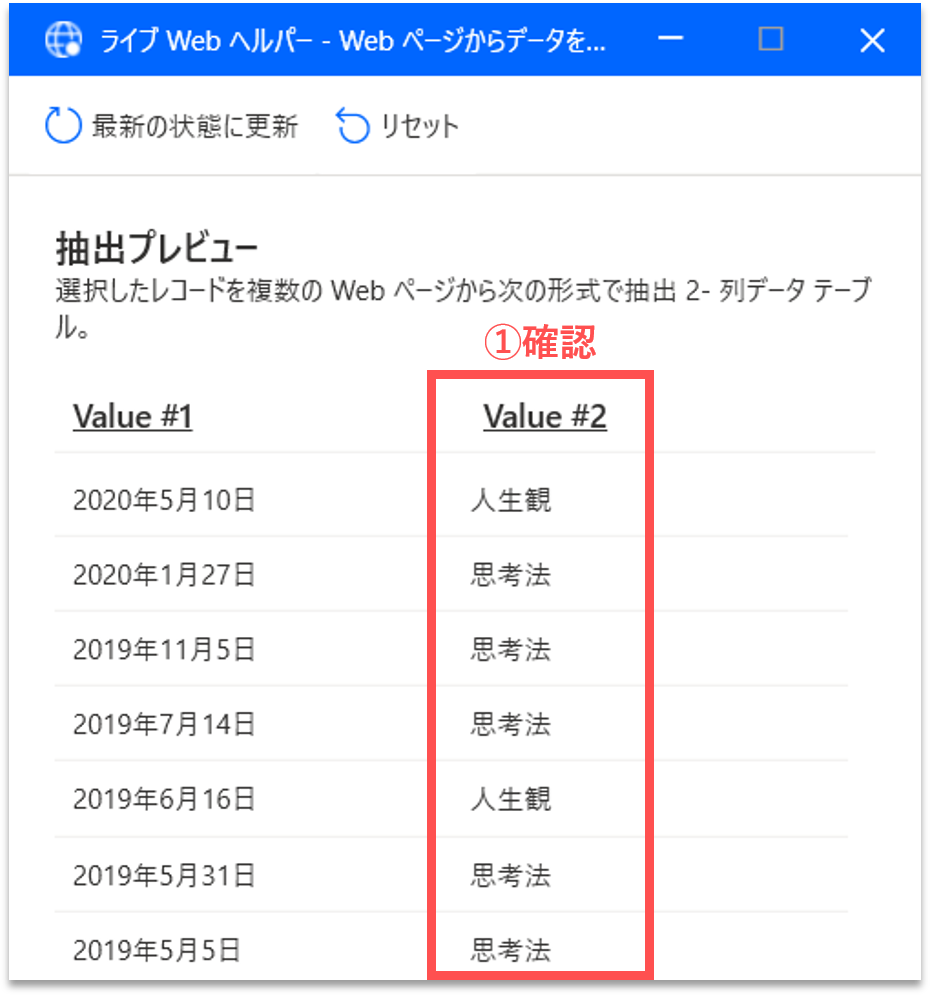
続けて、ブログ記事の「題名」を取得します。画面内の一番目に表示されたブログ記事の題名にカーソルを合わせて右クリックします。そして、「要素の値を抽出」を選択し、一覧の中から「テキスト:(’・・・’)」をクリックします。
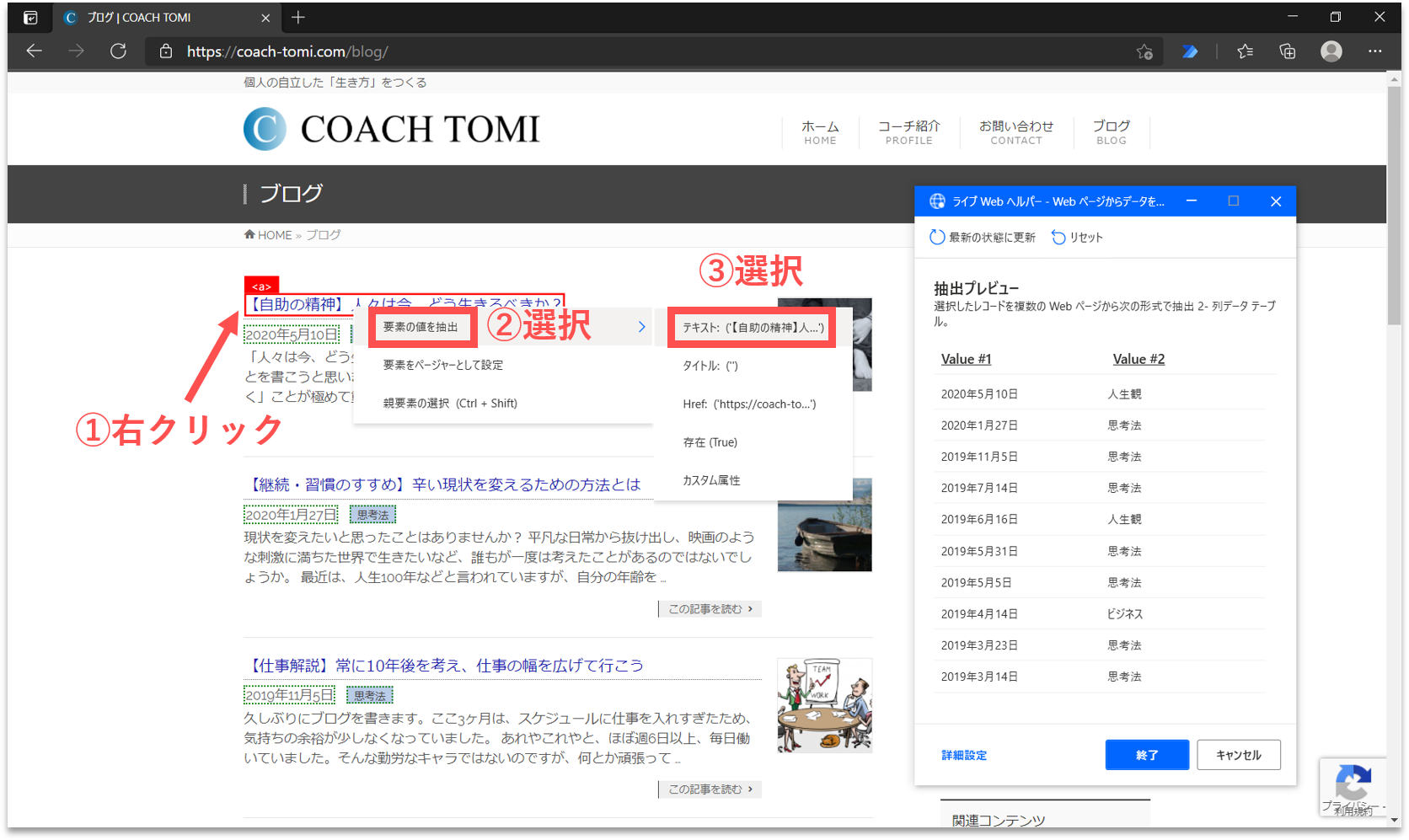
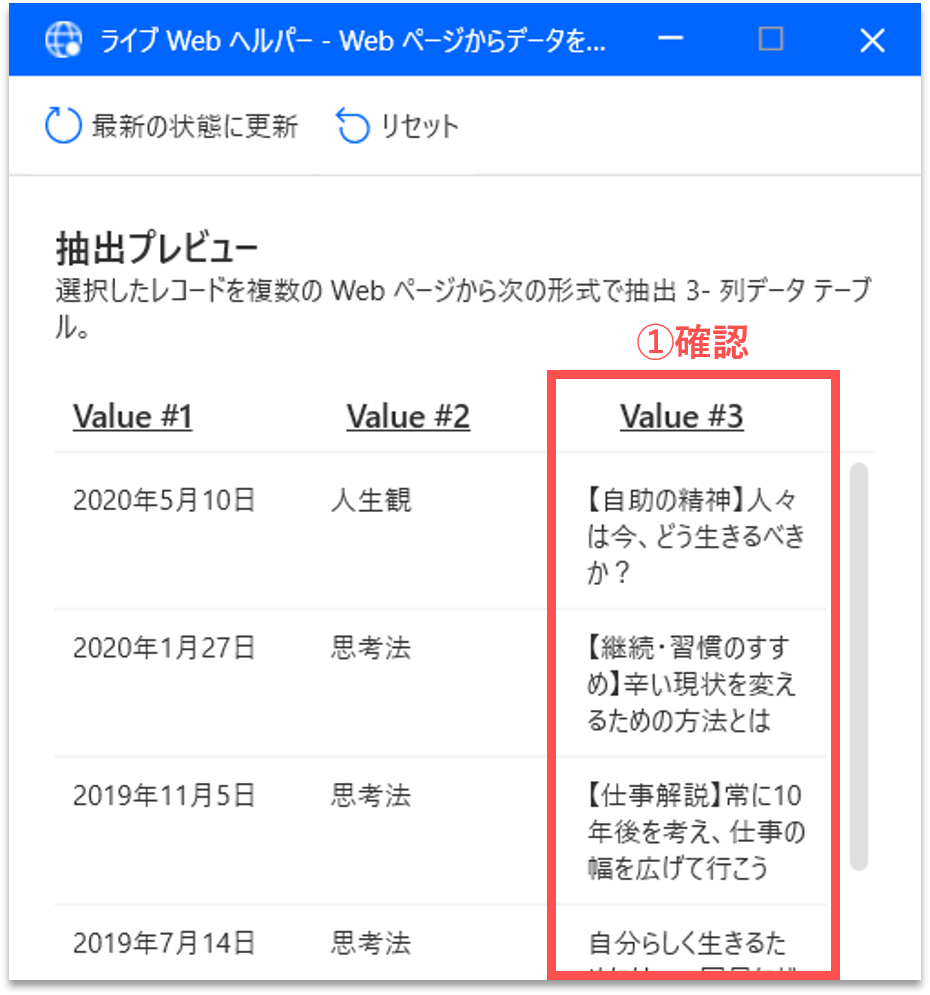
すると、「ライブWebヘルパー」パネルに、取得する構造化データのプレビューが表示されます。右端の列に題名のリストが追加されていることが確認できます。
【Step.9】URLの取得
最後に、ブログ記事の「URL」を取得します。画面内の一番目に表示されたブログ記事の題名にカーソルを合わせて右クリックします。そして、「要素の値を抽出」を選択し、一覧の中から「Href:(’・・・’)」をクリックします。
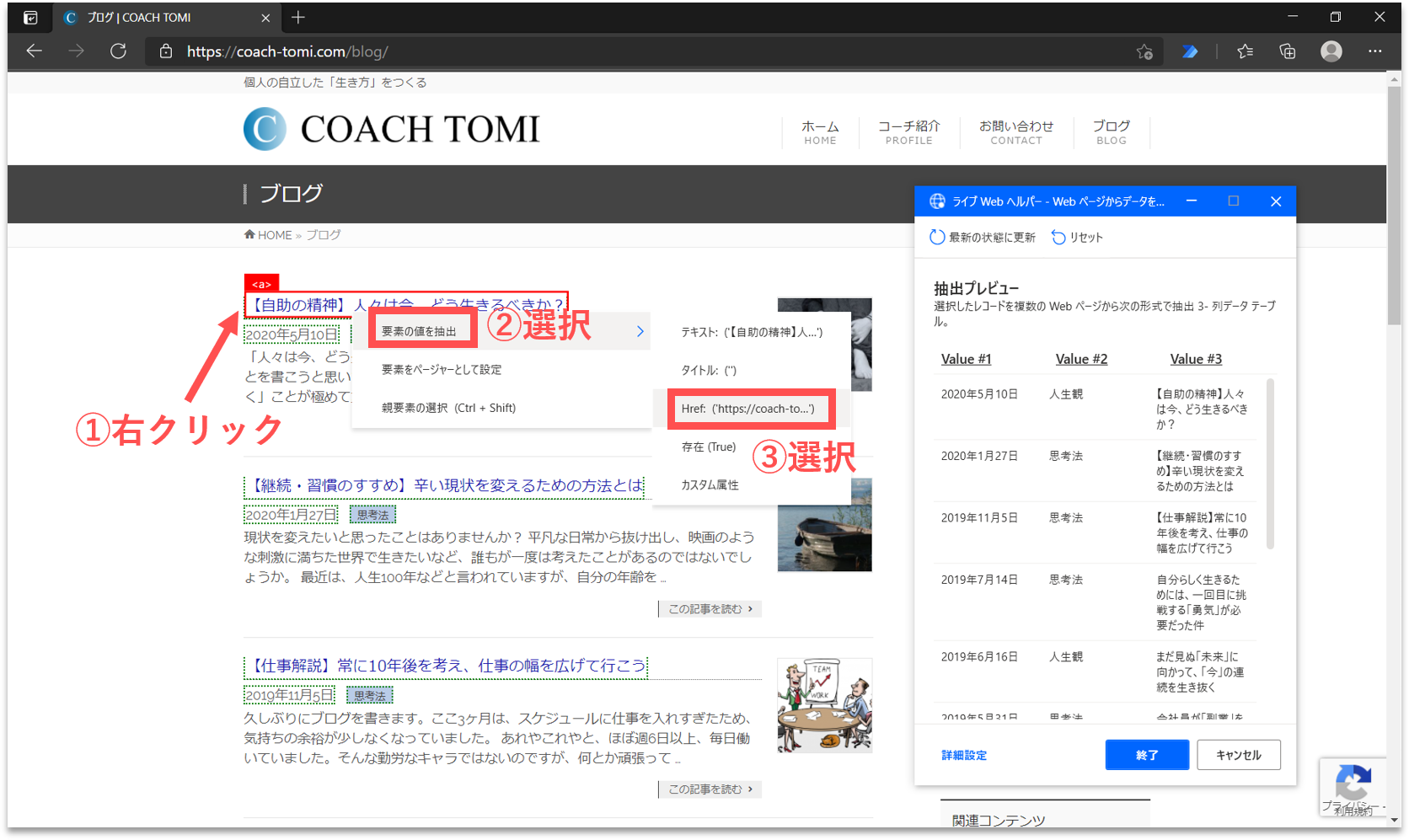
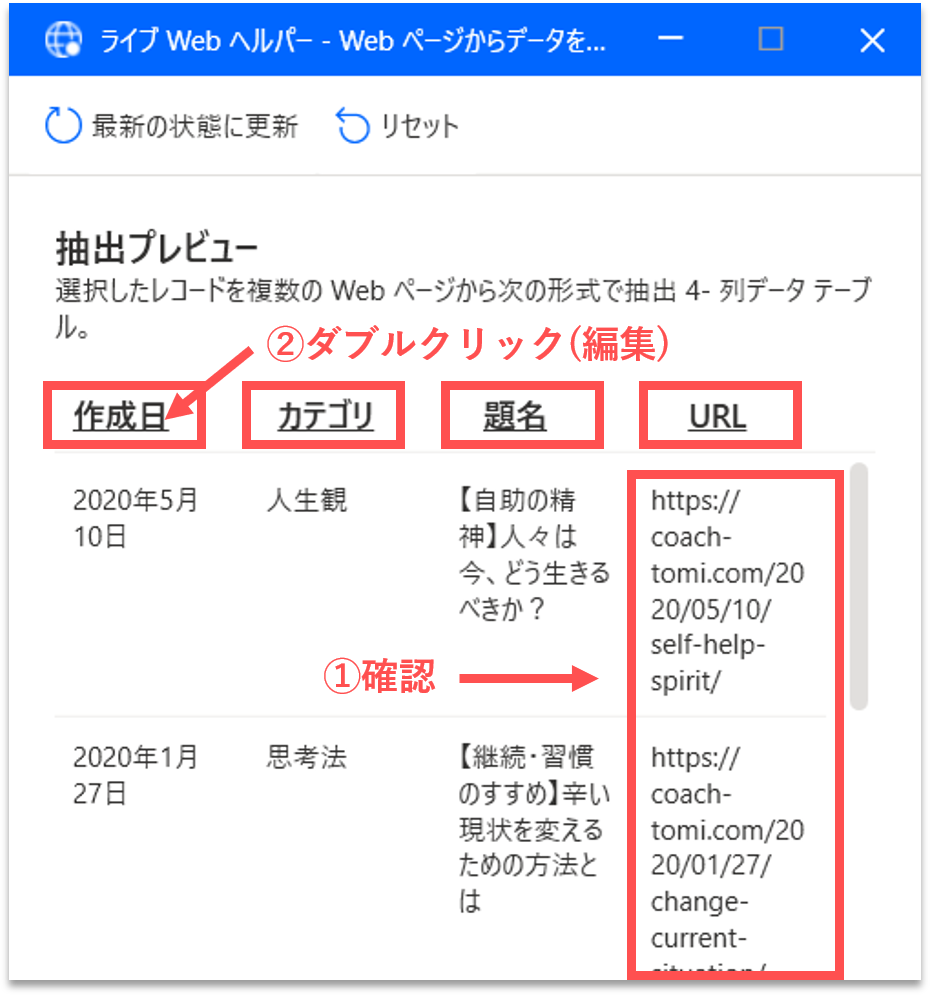
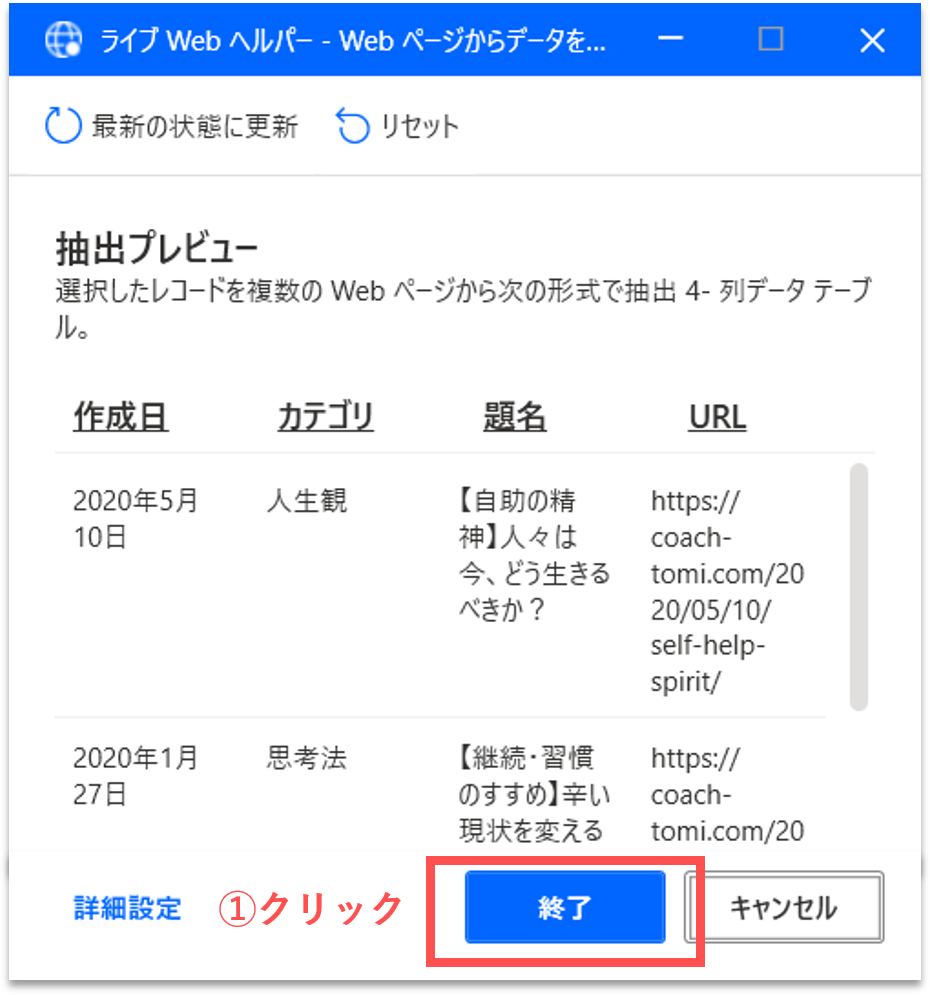
すると、「ライブWebヘルパー」パネルに、取得する構造化データのプレビューが表示されます。右端の列にURLのリストが追加されていることが確認できます。ここで、各列の項目名をダブルクリックして編集しておきましょう。これらはCSVファイルに出力する際の項目名となります。
【Step.10】ページ送りの設定
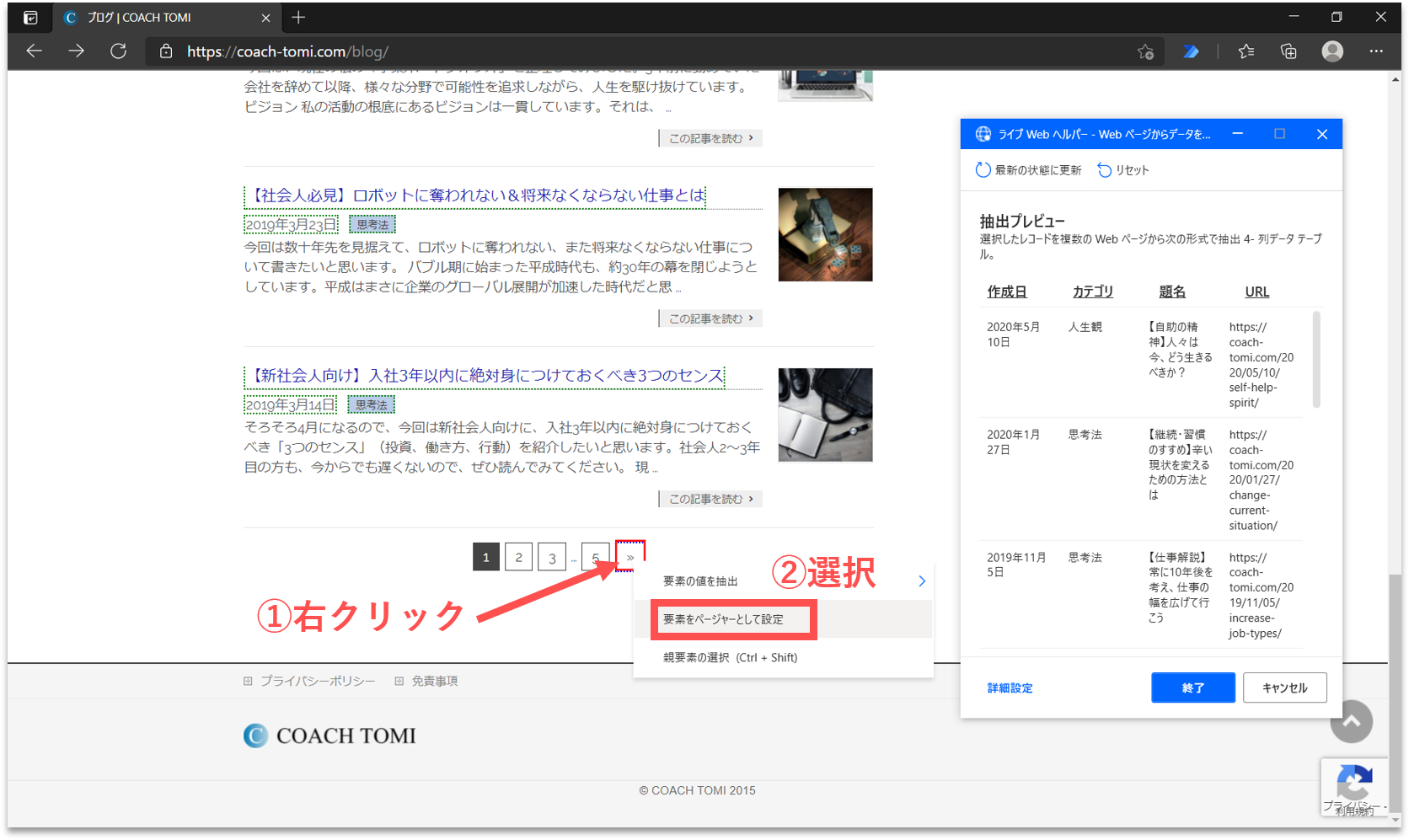
ページが複数にまたがる場合は、自動でページ送りするように設定する必要があります。事前に画面を一番下までスクロールして、ページ送りするリンクボタンを表示させます。そして、次のページに遷移するリンク(「次へ」、「Next」、「>>」など)を右クリックし、「要素をページャーとして設定」を選択します。
【Step.11】CSSセレクタの編集
「ライブWebヘルパー」パネルの「詳細設定」ボタンをクリックします。
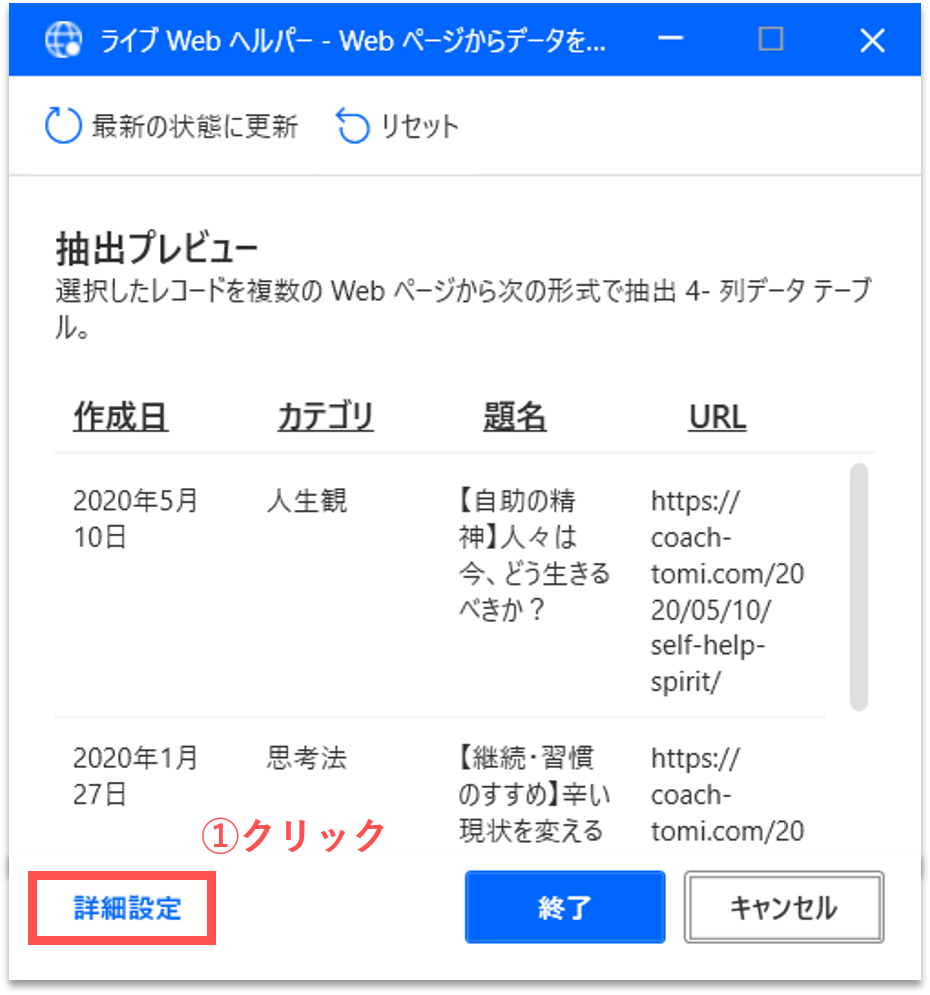
「詳細設定」パネルが表示され、各CSSセレクタの値が確認できます。CSSセレクタとは、Webサイト上の各要素の位置情報のようなものです。CSSセレクタが極端に長いと、Webサイトの構造が少し変化するだけで、要素を正しく指定することができなくなります。今回は、「検索結果の次のページのCSSセレクタ」の値が若干長いため、下記の値に変更しておきます。詳細は割愛しますが、CSSセレクタは、各種ブラウザの開発者ツールなどで取得できます。編集後に「OK」ボタンをクリックします。
#content > div > div.paging > a.next_link
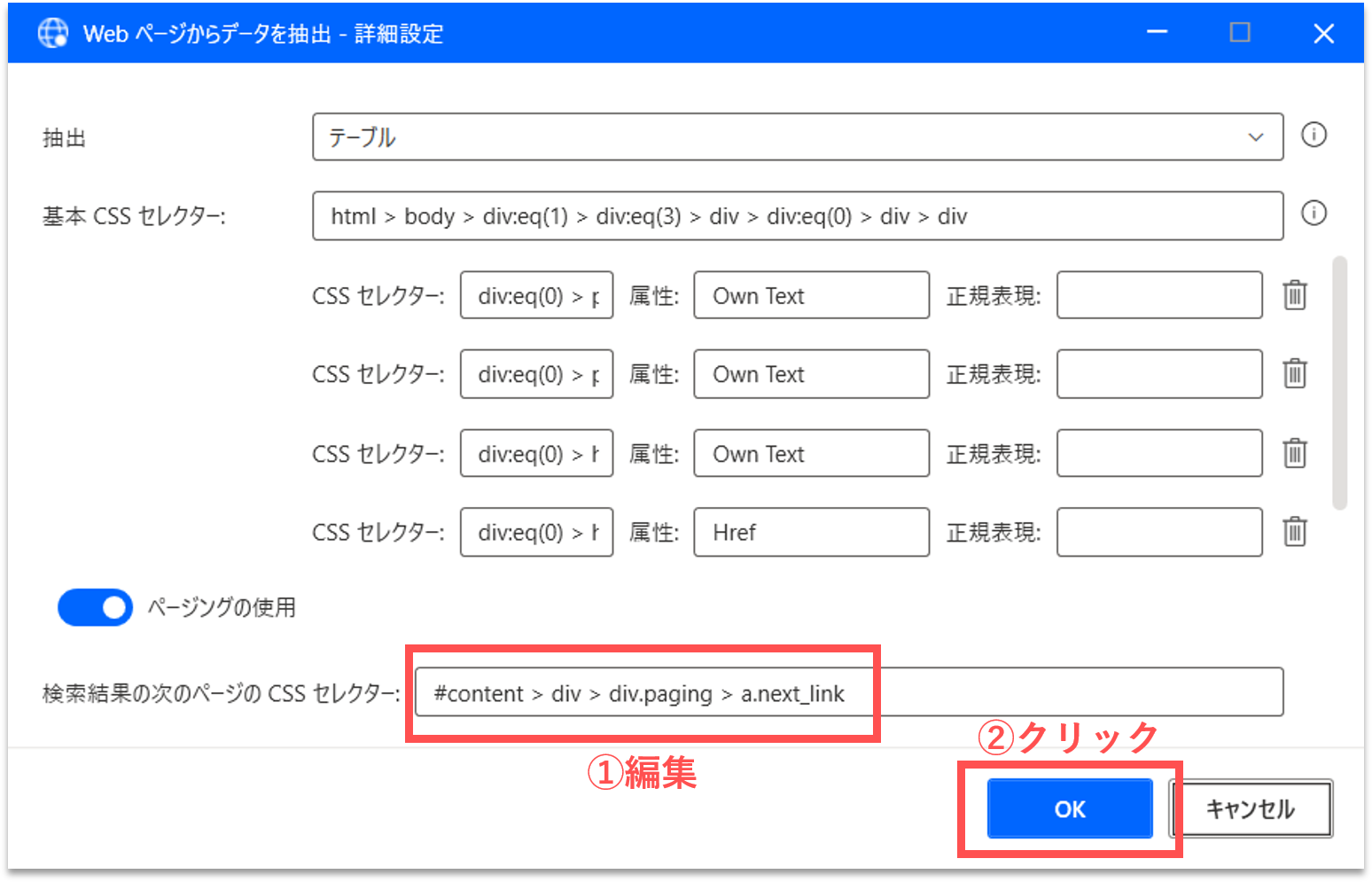
続けて、「ライブWebヘルパー」パネルで「終了」ボタンをクリックします。
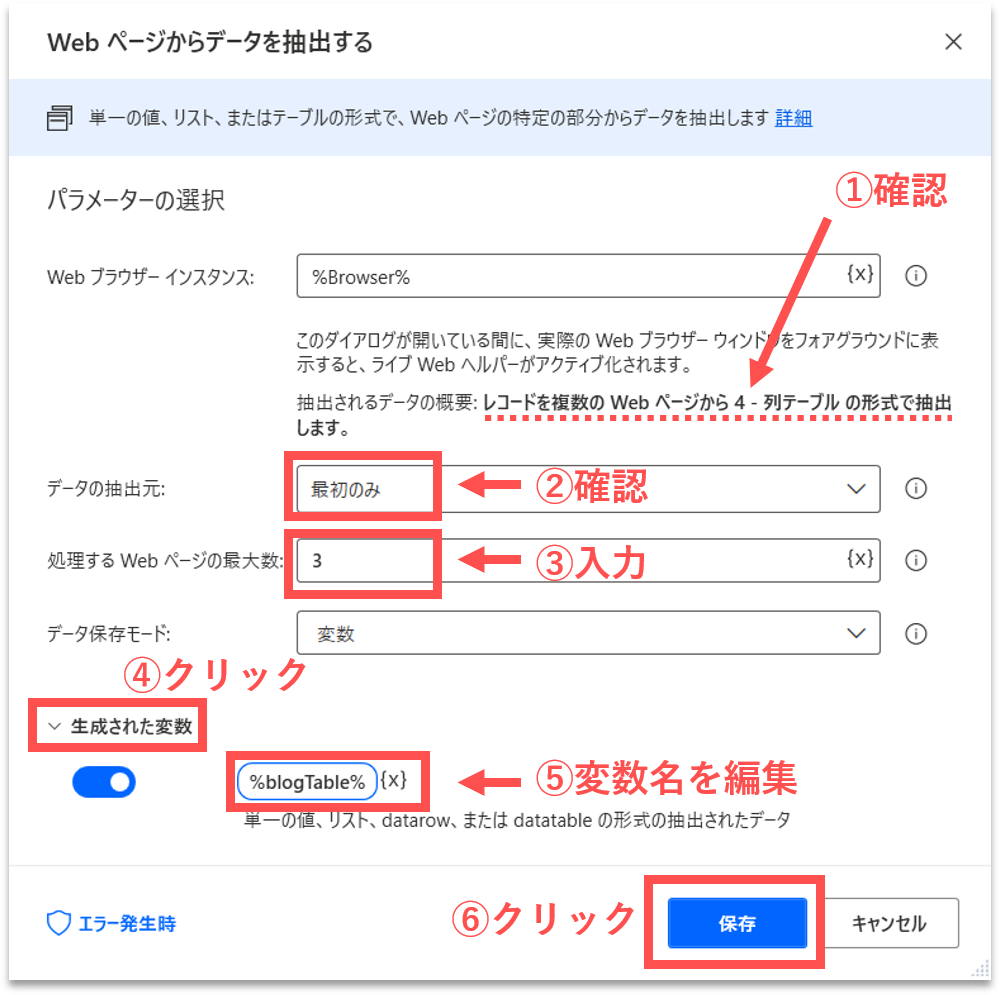
【Step.12】ページ数の設定
再び、プロパティ設定の画面が表示されます。「抽出されるデータの概要」エリアに、取得する構造化データの概要が表示されていることが、また、「データの抽出元」は「最初のみ」になっていることが確認できます。今回は、「処理するWebページの最大数」は3に設定しておきます。(※すべてのページから取得する場合は、「データの抽出元」を「すべて使用できます」に設定します。)
続けて、「生成された変数」をクリックして、変数名が「%DataFromWebPage%」になっていることを確認します。「生成された変数」には、取得した構造化データが格納されます。基本的に、変数名はその中身を推測できる名称をつけるべきです。今回は、「%blogTable%」に変更します。最後に、「保存」ボタンをクリックします。
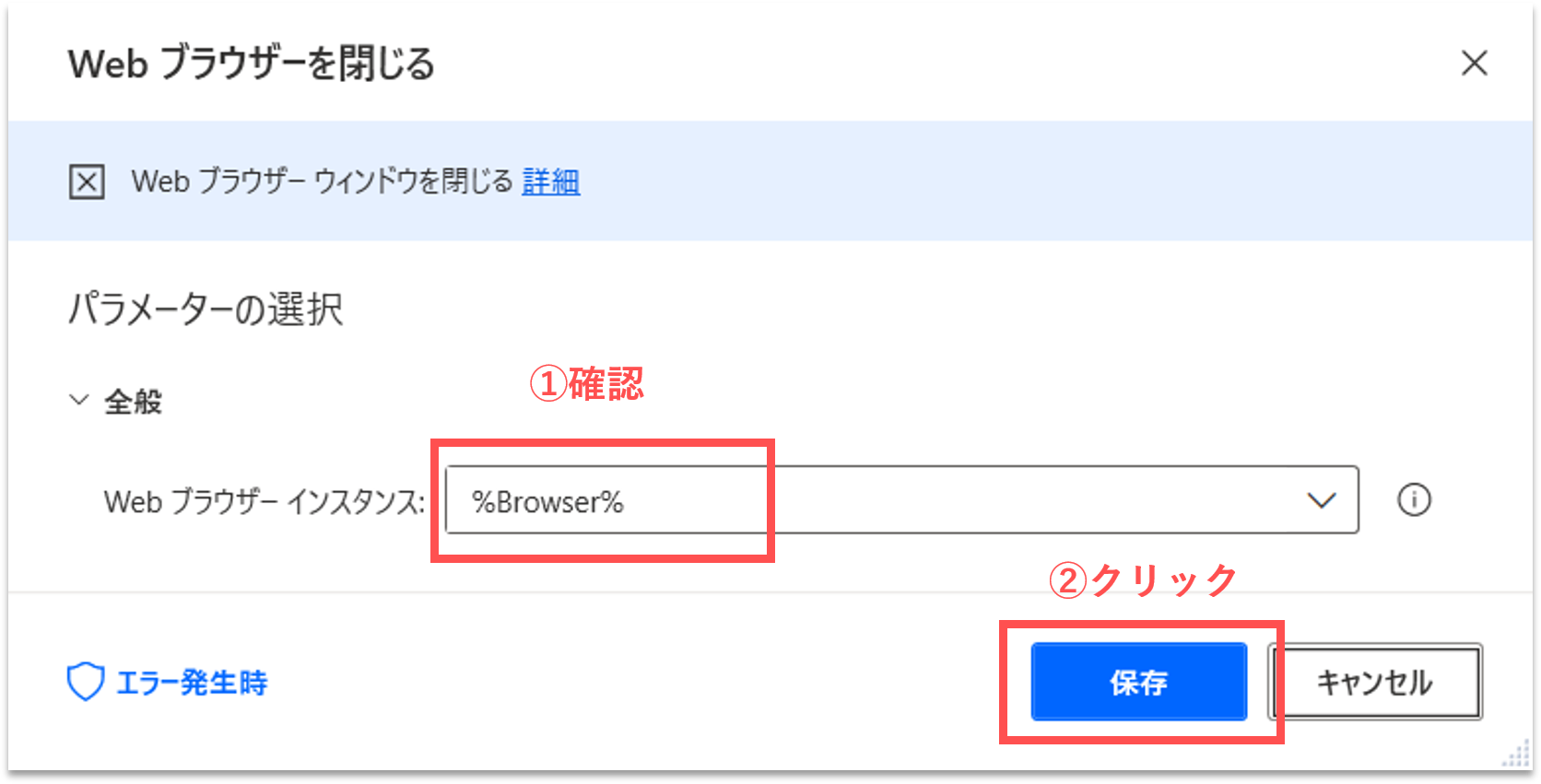
【Step.13】Webブラウザを閉じる
Webブラウザを閉じるために、アクションを追加したいと思います。画面左側のアクション検索窓に「閉じる」と入力します。「Webブラウザを閉じる」アクションを、フロー内の「Webページからデータを抽出する」アクションの直下にドラッグ&ドロップします。
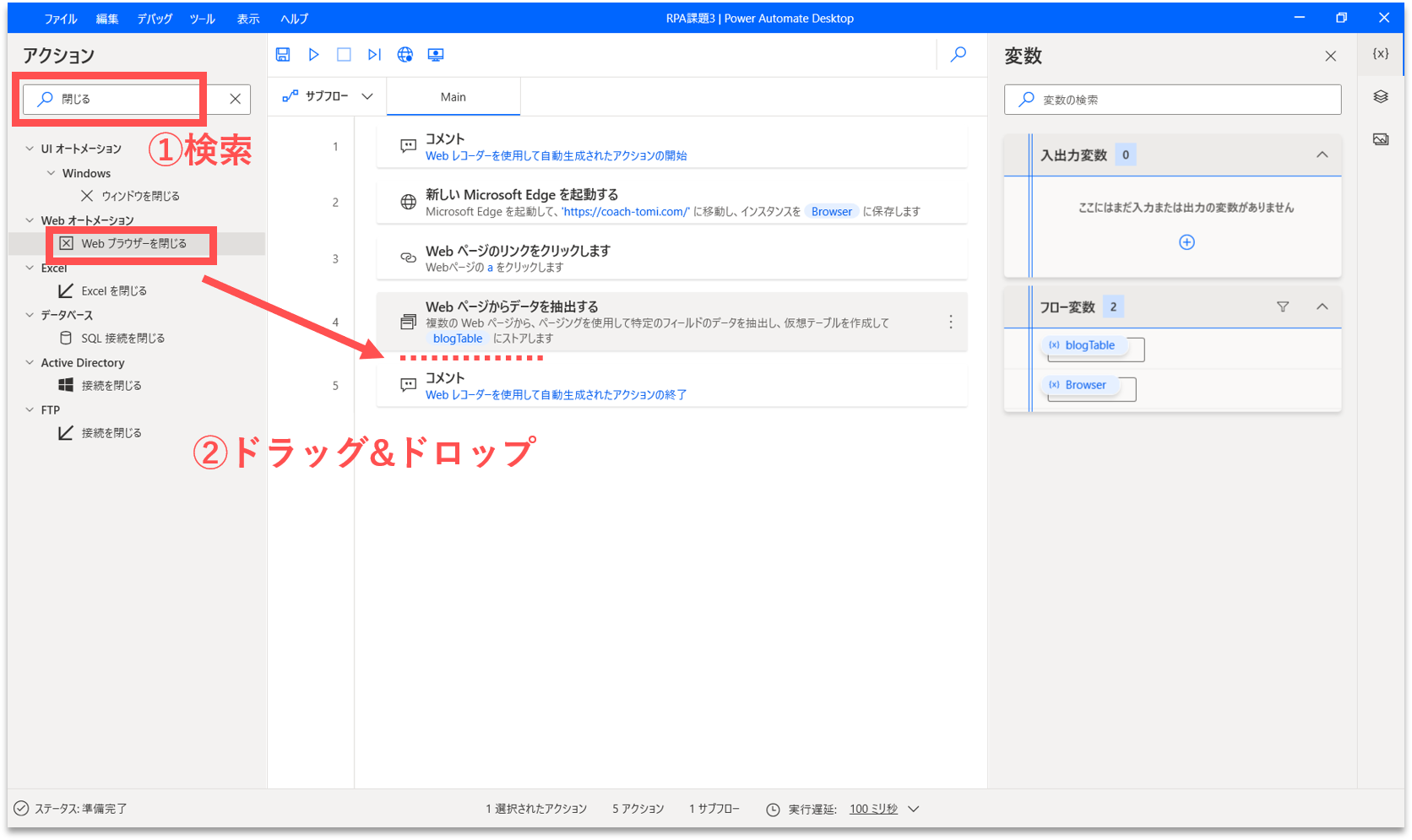
すると、プロパティ設定の画面が開きます。「Webブラウザインスタンス」に「%Browser%」が設定されていることを確認して、そのまま「保存」ボタンをクリックします。「%Browser%」は、最初に開いたWebブラウザのインスタンス名です。
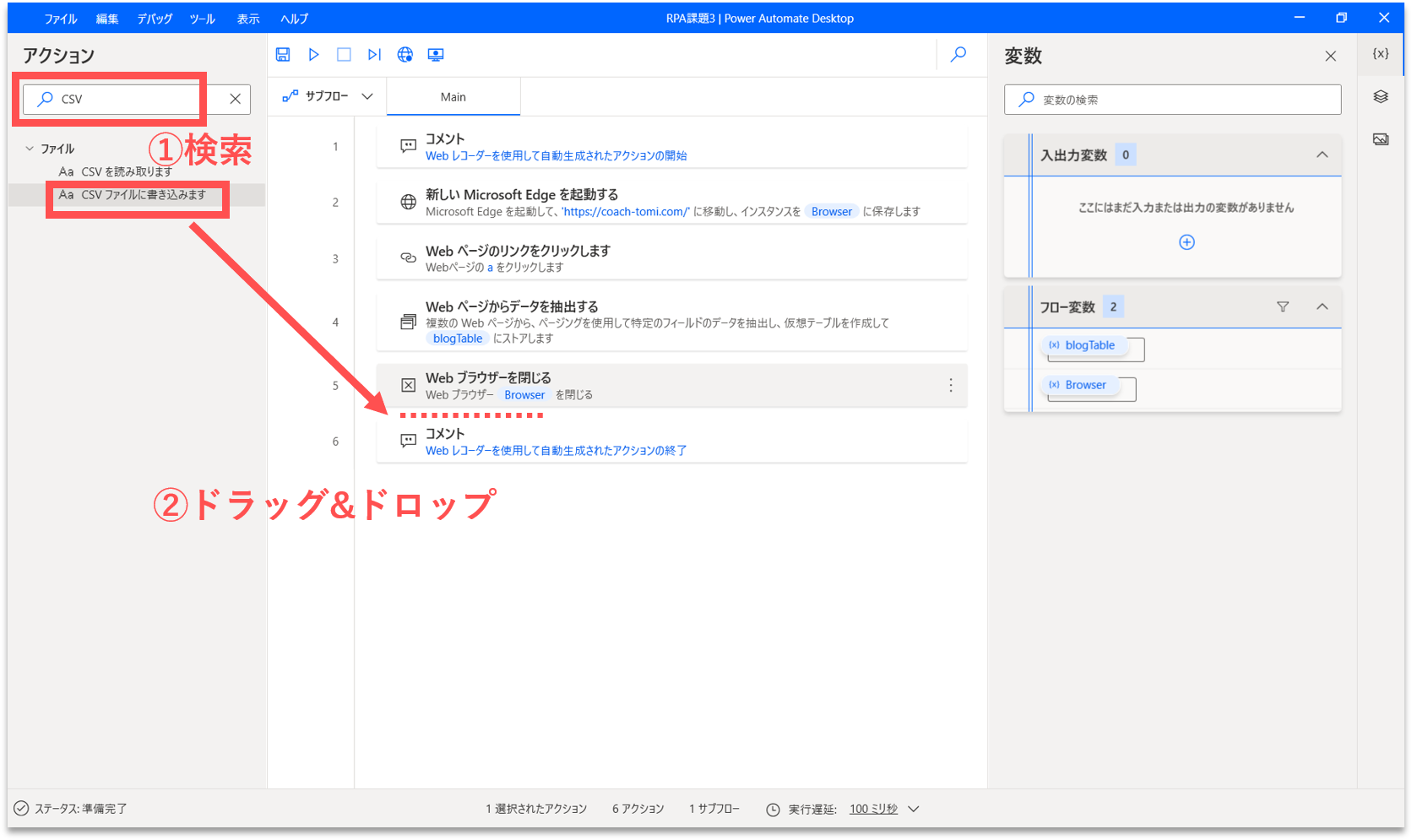
【Step.14】CSVファイルに出力
フローの最後に、CSVファイルに構造化データを出力する処理を追加します。画面左側のアクション検索窓に「CSV」と入力します。「CSVファイルに書き込みます」アクションを、フロー内の「Webブラウザを閉じる」アクションの直下にドラッグ&ドロップします。
すると、プロパティ設定の画面が開きます。下表の通りに各プロパティの値を編集します。これで、準備が完了しました。
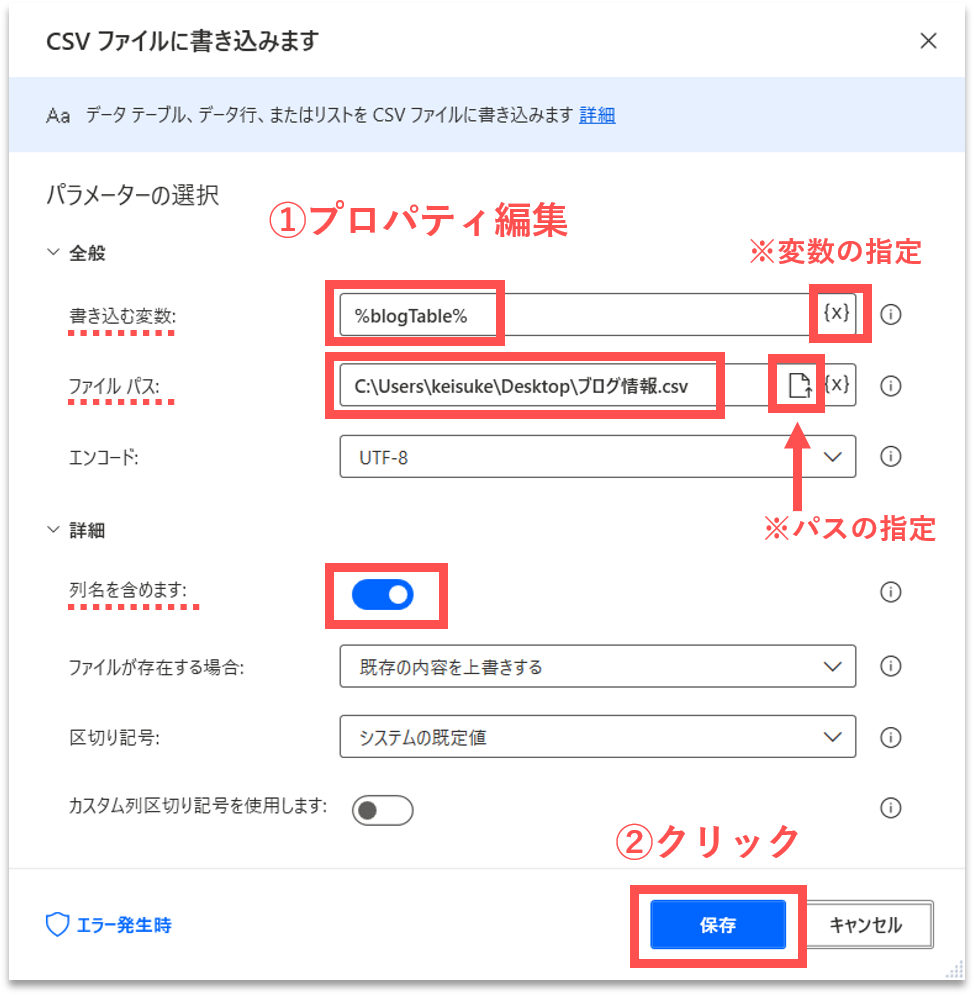
| No. | プロパティ項目 | 設定する値 |
|---|---|---|
| 1 | 書き込む変数 | %blogTable% ※{x}アイコンをクリックして、作成済みの変数を選択することもできます。 |
| 2 | ファイルパス | ファイルの保存先(任意) ※ファイルアイコンをクリックして、ダイアログで保存先を指定することもできます。 |
| 3 | 列名を含めます | ON |
【Step.15】フローの実行
上部の「実行」アイコンをクリックし、このフローを実行してみましょう。なお、フローの作成画面から実行すると、「デバッグモード」で実行されるようで、処理速度が遅いです。実際の運用時には、管理画面から実行ボタンをクリックしてフローを実行しましょう。
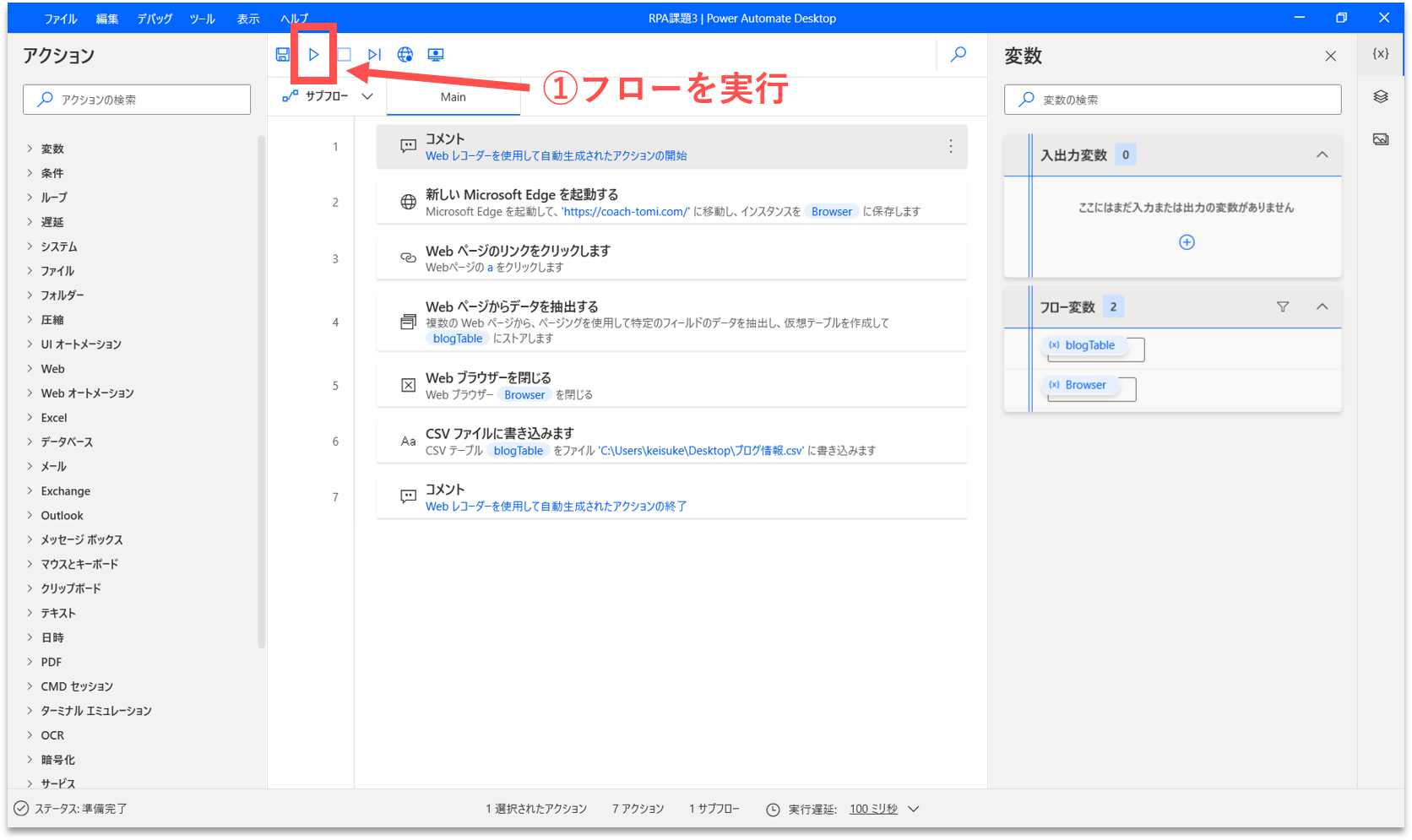
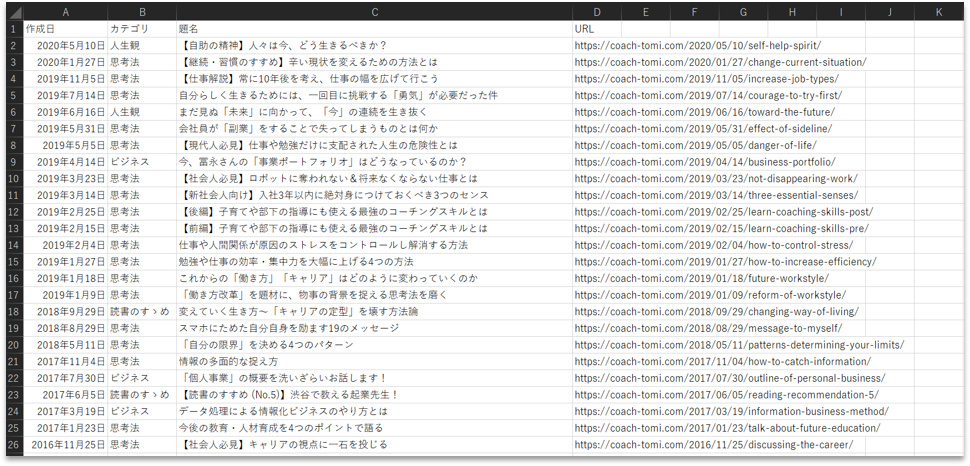
如何でしょうか。Webブラウザが起動して、ブログ記事の一覧画面をページ送りしていったと思います。そして、取得した構造化データのCSVファイルが、指定した保存場所に作成されました。上手く、Webサイトからブログ記事の見出し情報を取得することができています。
まとめ
今回は、Webサイトからブログ記事の見出し情報(構造化データ)を取得して、CSVファイルに出力する処理を自動化しました。下記の点を理解して、他の業務にも応用できるようにしましょう。
- Webレコーダーによる自動記録
- Webサイト上の構造化データ取得
- 変数名の変更
- CSVファイルへの出力
関連記事
 2024年7月13日 【技術Tips:3】Webデータ抽出で正規表現オプションを使う/Power Automate for desktop
2024年7月13日 【技術Tips:3】Webデータ抽出で正規表現オプションを使う/Power Automate for desktop 2024年3月7日 【1.導入編】RPAのセレクタ設定の基礎知識(Power Automate for desktop版)
2024年3月7日 【1.導入編】RPAのセレクタ設定の基礎知識(Power Automate for desktop版) 2023年12月16日 RPA追加トレーニング(Lv.2 中級)
2023年12月16日 RPA追加トレーニング(Lv.2 中級) 2022年2月5日 【時系列マップ解説】過去に実践してきたプログラミング言語の具体的な勉強方法と順番
2022年2月5日 【時系列マップ解説】過去に実践してきたプログラミング言語の具体的な勉強方法と順番