
RPAの入門として、UiPathの使い方を紹介していきます。今回は、Webサイトからブログ記事の見出し情報(繰り返しデータ)を取得して、CSVファイルに出力する処理を自動化したいと思います。
【初心者歓迎・RPA個人講座】RPAを一から学ぶITスクール
UiPathのワークフロー構築
【Step.1】Mainワークフローを開く
ワークフローを構築していくために、画面左下の「Activities」タブを選択し、画面中央の「Open Main Workflow」をクリックします。

【Step.2】Webブラウザの起動
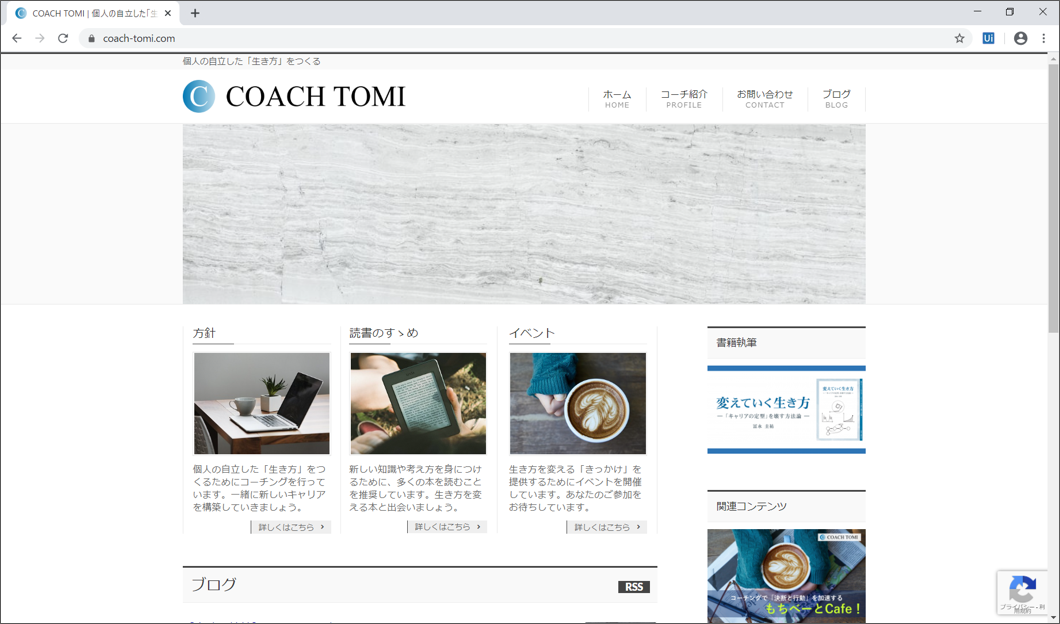
Webブラウザを起動して、こちらのWebサイトにアクセスします。ブラウザはこのまま開いておきます。
【Step.3】Webレコーディングの準備
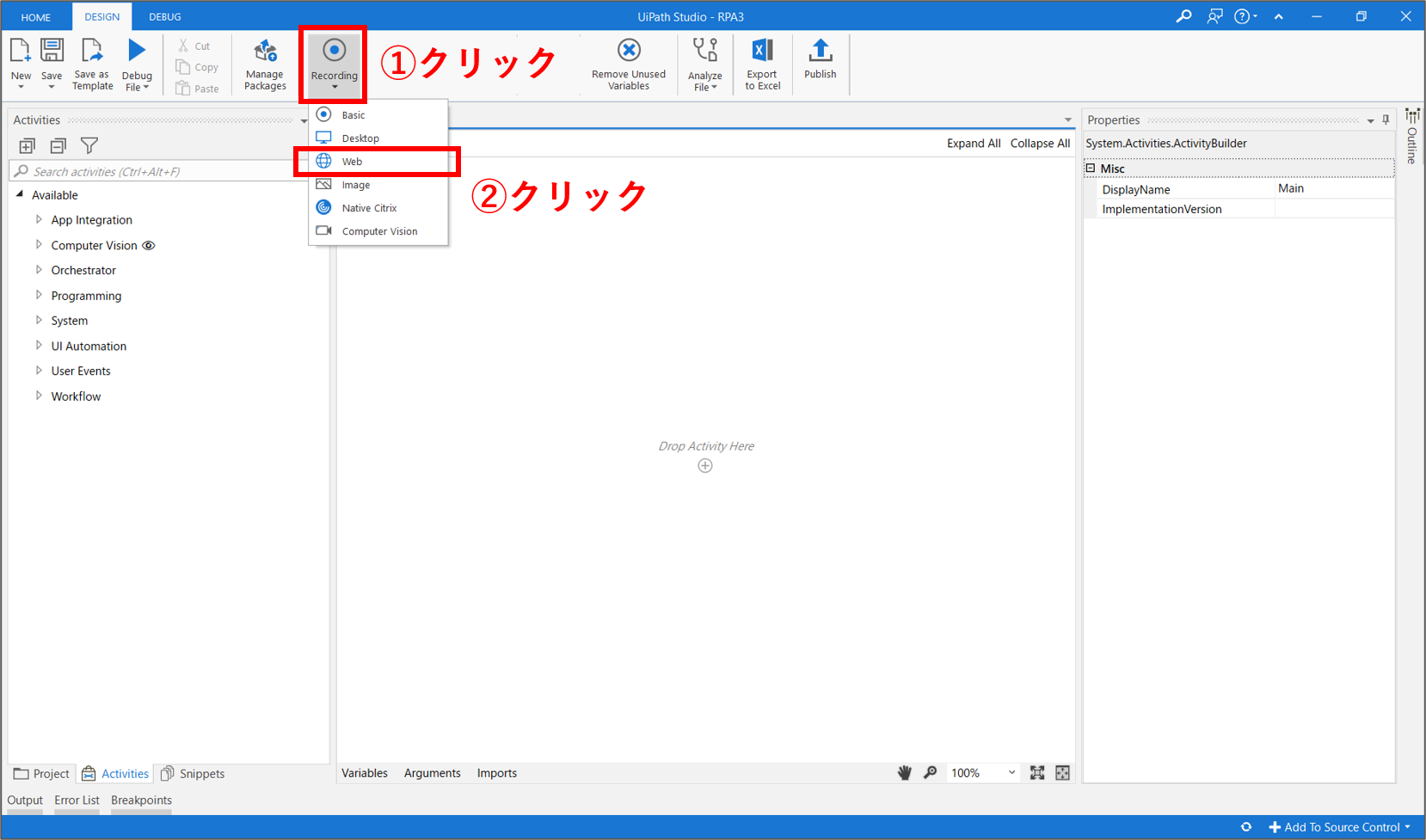
Webブラウザの操作を自動記録させるために、Webレコーディングを起動させます。上部パネルの「Recording > Web」を選択します。
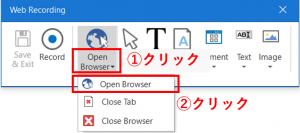
「Web Recording」パネルが起動します。一番初めに開くWebサイトのURLを設定するために、「Open Browser > Open Browser」を選択します。
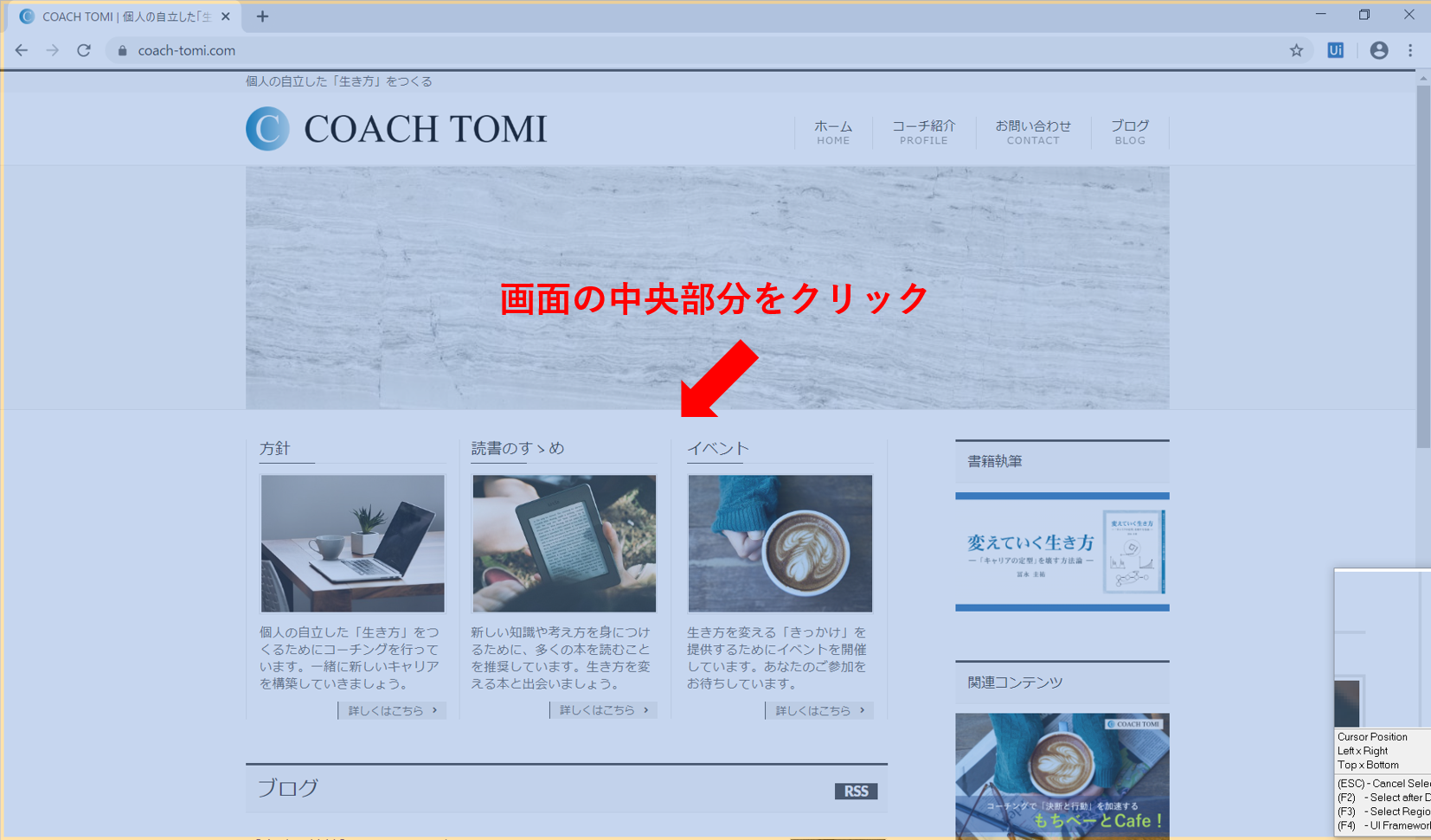
そして、先ほど開いておいたWebブラウザの中央部分にカーソル(黄色の枠)を合わせます。この状態でクリックします。クリック後にURLが表示されますので、確認して「OK」をクリックします。これで、Webレコーディングの準備が完了しました。
【Step.4】Webレコーディングの開始
ここから、Webブラウザの操作を自動記録していきます。操作内容がそのまま記録されるので慎重に実行してください。「Web Recording」パネルが表示されていると思うので、「Record」を選択します。
ヘッダーメニューの「ブログ」にカーソル(黄色の枠)を合わせてクリックします。ブログ記事の一覧画面に遷移します。
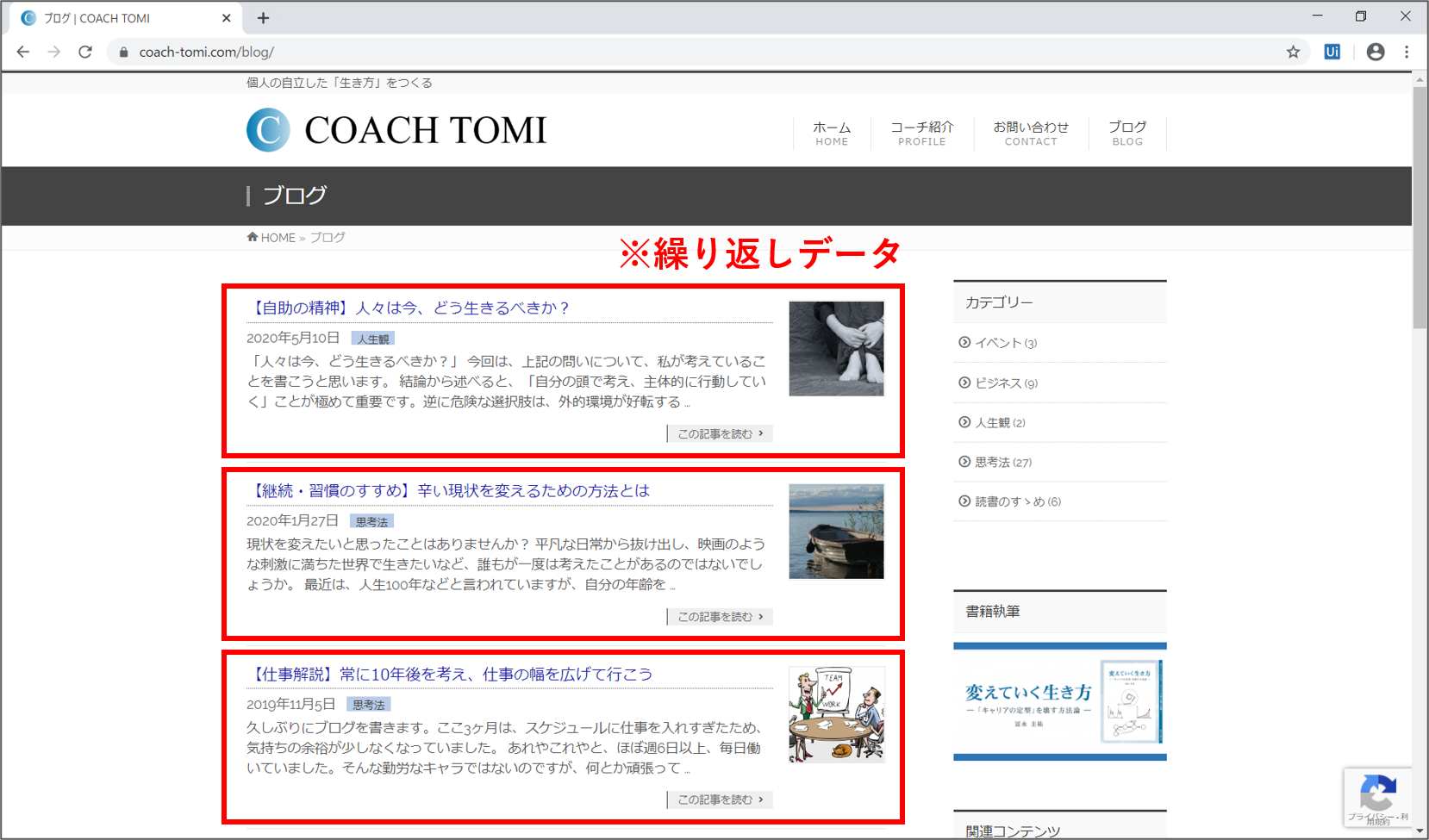
【Step. 5】繰り返しデータの取得
今回は、ブログ記事の見出し情報(繰り返しデータ)の中から、下記の項目を取得したいと思います。取得するデータの最大件数は20件とします。
- 作成日
- カテゴリー
- 題名
- URL(記事の詳細ページ)
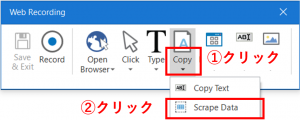
ブラウザ上に表示されたデータを取得するためには、「Esc」キーを押して、一度Webレコーディングモードを解除します。「Esc」キーを押すと、Webレコーディングモードが解除され、再び「Web Recording」パネルが表示されます。この状態での操作は記録されません。繰り返しデータを取得するために、「Copy > Scrape Data」を選択します。
「Select Element」の設定画面が表示されます。「Scrape Data」の使い方の手順が記載されています。では、「Next」をクリックして、実際に繰り返しデータを取得してみましょう。
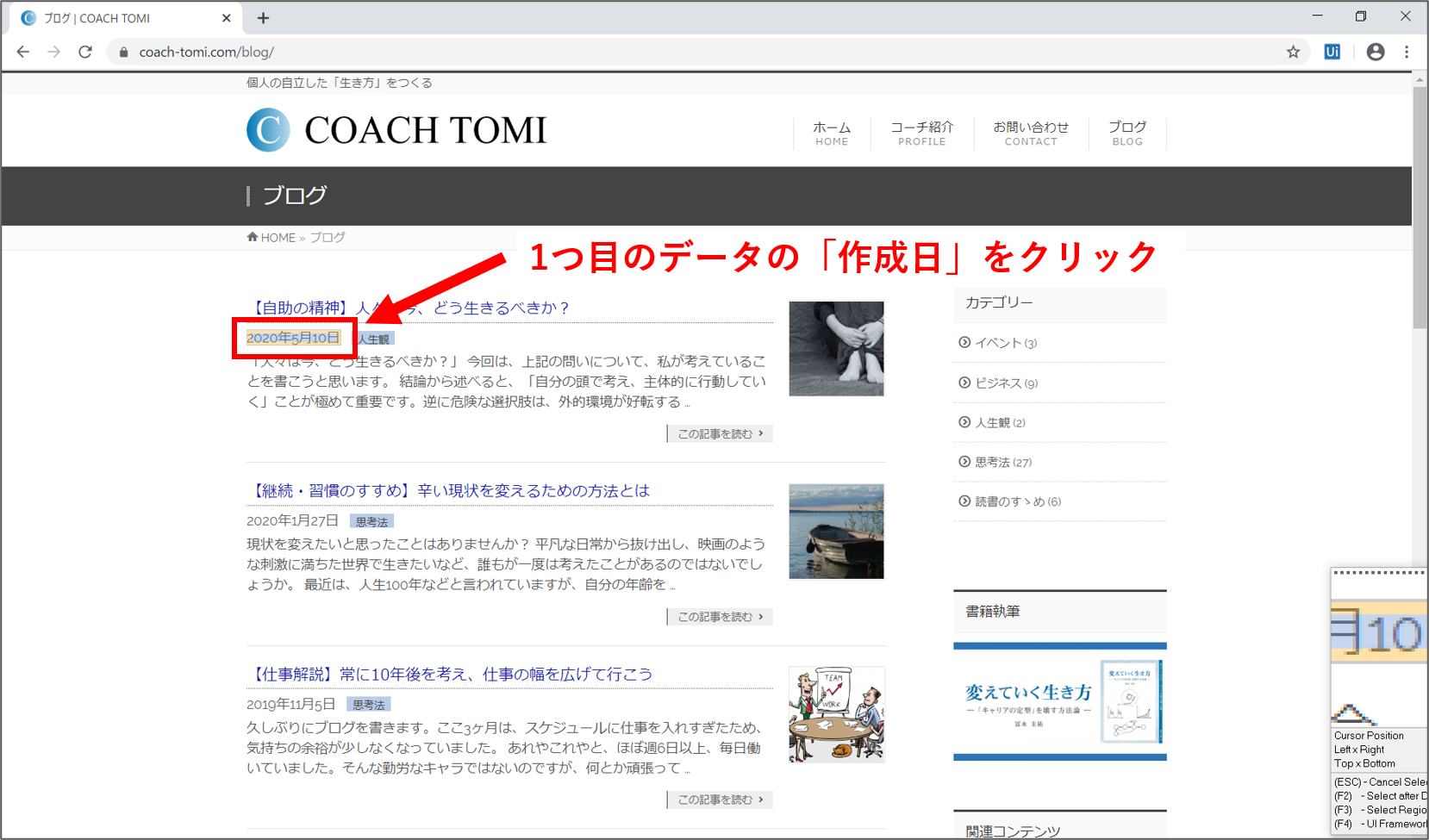
【Step.6】作成日の取得
先ずは、ブログ記事の「作成日」を取得します。画面内の一番上に表示されたブログ記事の作成日にカーソルを合わせると、黄色の枠で囲まれます。その状態でクリックします。
「Select Second Element」の設定画面が開きます。重要なポイントですが、Scrape Dataで繰り返しデータを取得する場合は、データを二ヶ所指定してあげる必要があります。「Next」ボタンを押します。
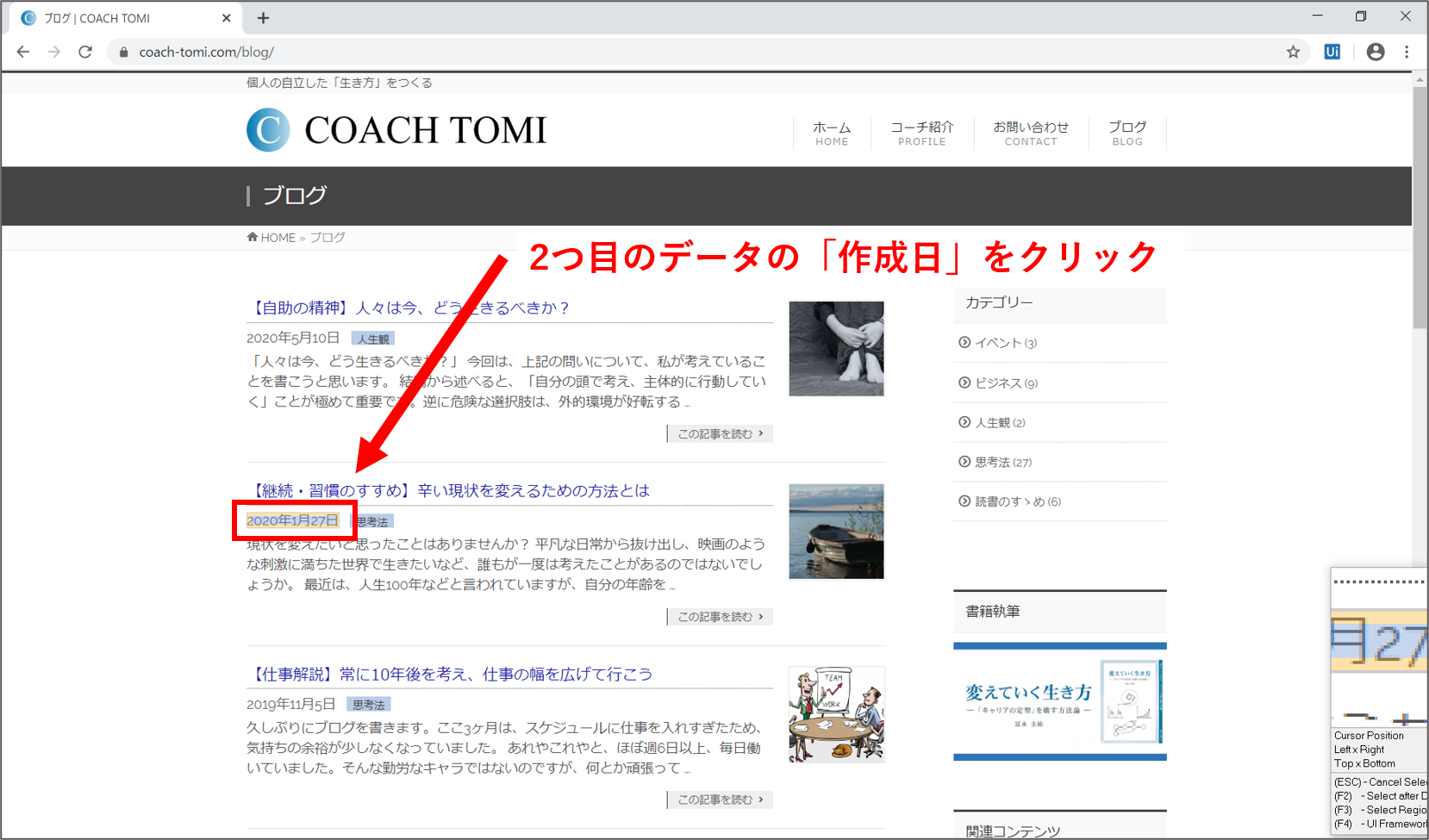
続けて、2つ目に表示されたブログ記事の作成日をクリックします。
正しく指定できれば、「Configure Columns」の設定画面が開きます。項目名(作成日)を入力して、「Next」ボタンをクリックします。ここで入力した項目名は、最後にCSVファイルに出力した際の列名に反映されます。
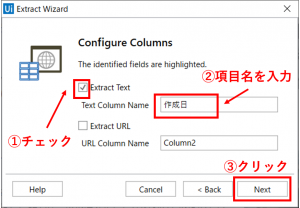
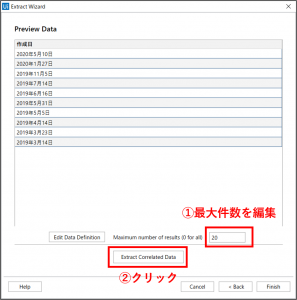
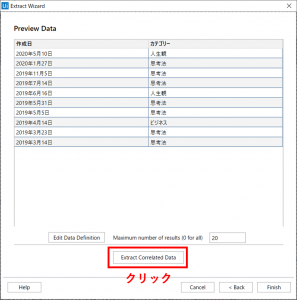
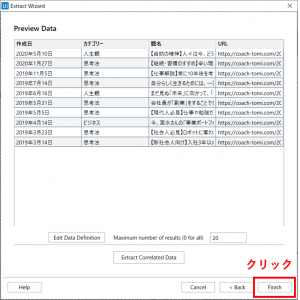
「Preview Data」の設定画面が開きます。この画面では、実際に取得されるデータが確認できます。取得するデータの最大件数を20件に変更しておきます(すべてのデータを取得したい場合は値を0に設定)。引き続き、他のデータ項目を取得するので、「Extract Correlated Data」ボタンをクリックします。
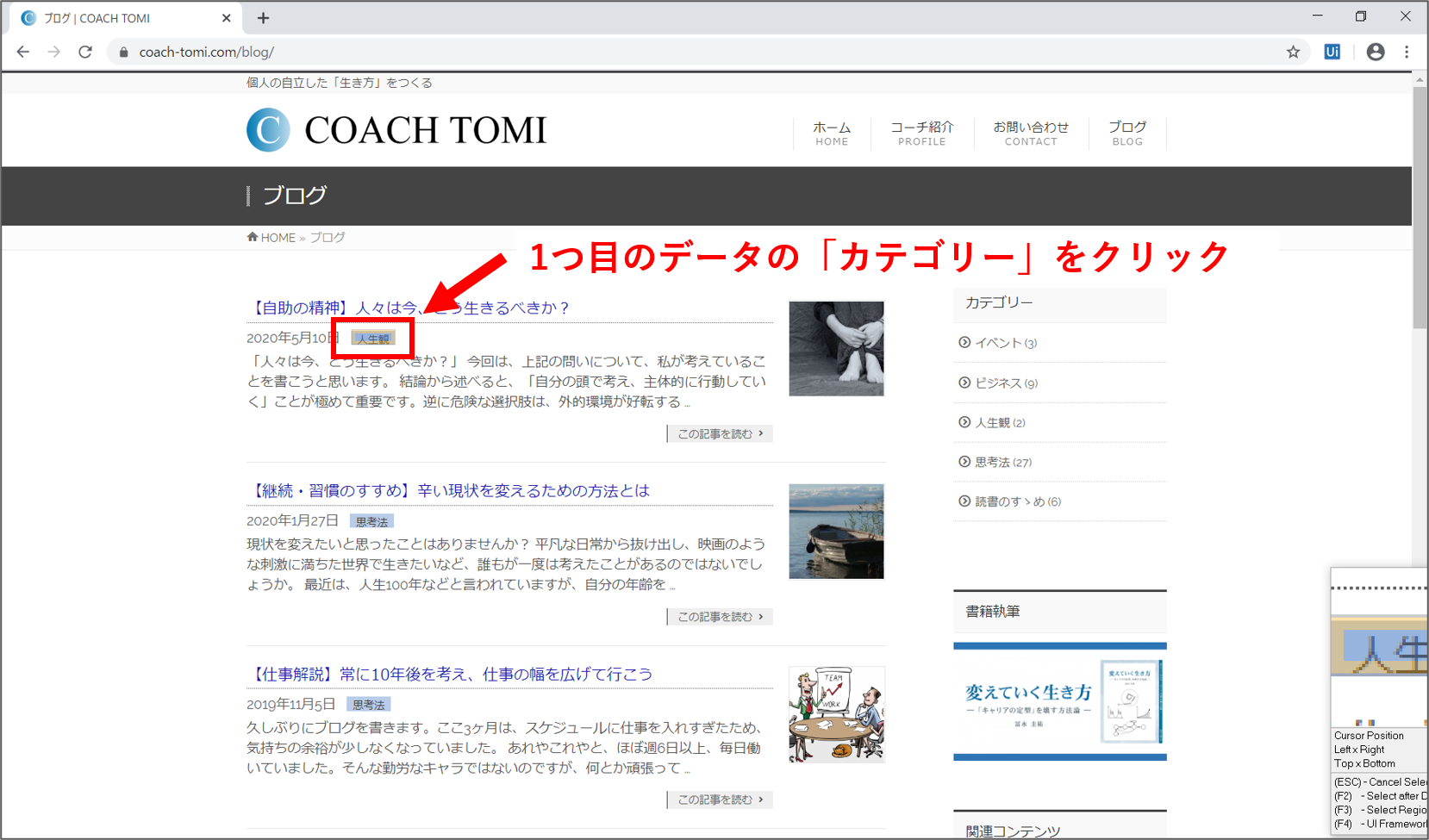
【Step.7】カテゴリーの取得
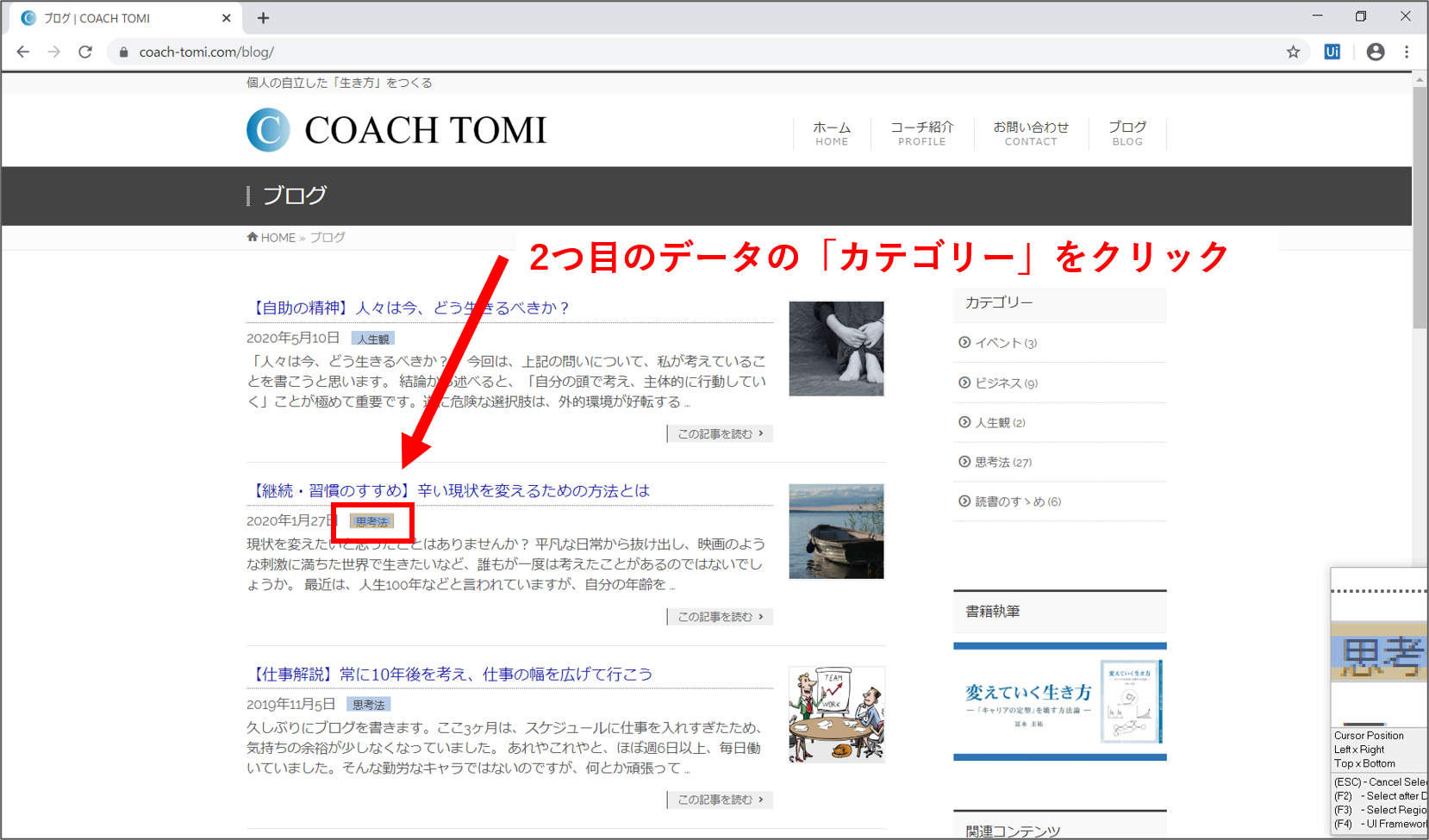
次は、ブログ記事の「カテゴリー」を取得します。画面内の一番上に表示されたブログ記事のカテゴリーにカーソルを合わせると、黄色の枠で囲まれます。その状態でクリックします。
「Select Second Element」の設定画面が開きます。「Next」ボタンを押します。続けて、2つ目に表示されたブログ記事のカテゴリーをクリックします。
正しく指定できれば、「Configure Columns」の設定画面が開きます。項目名(カテゴリー)を入力して、「Next」ボタンをクリックします。
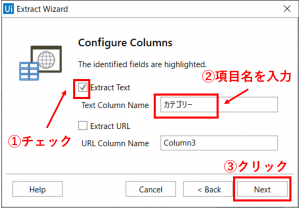
「Preview Data」の設定画面が開きます。引き続き、他のデータ項目を取得するので、「Extract Correlated Data」ボタンをクリックします。
【Step.8】題名とURLの取得
最後は、ブログ記事の「題名」と「URL」を取得します。画面内の一番上に表示されたブログ記事の題名にカーソルを合わせると、黄色の枠で囲まれます。その状態でクリックします。
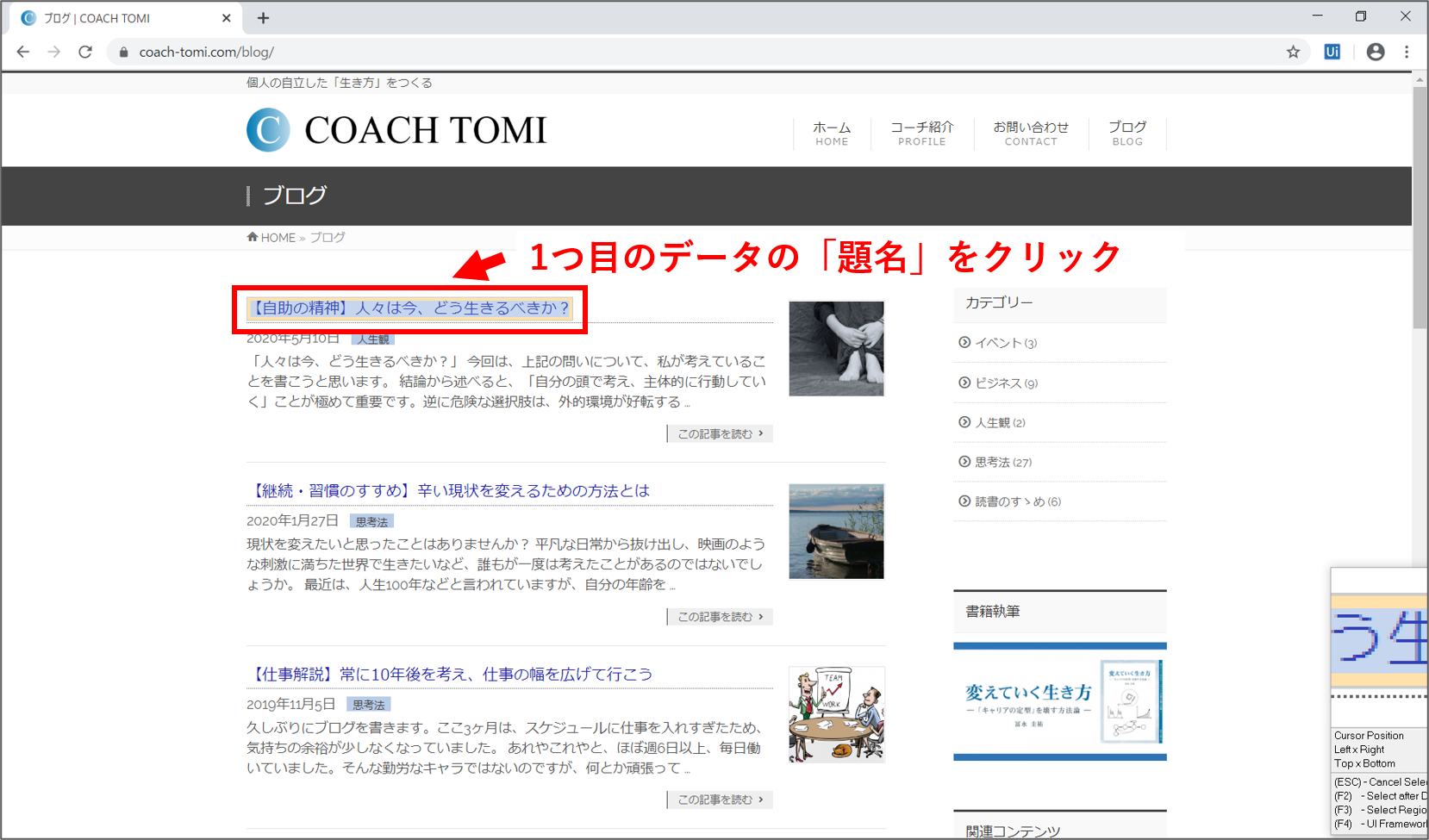
「Select Second Element」の設定画面が開きます。「Next」ボタンを押します。続けて、2つ目に表示されたブログ記事の題名をクリックします。
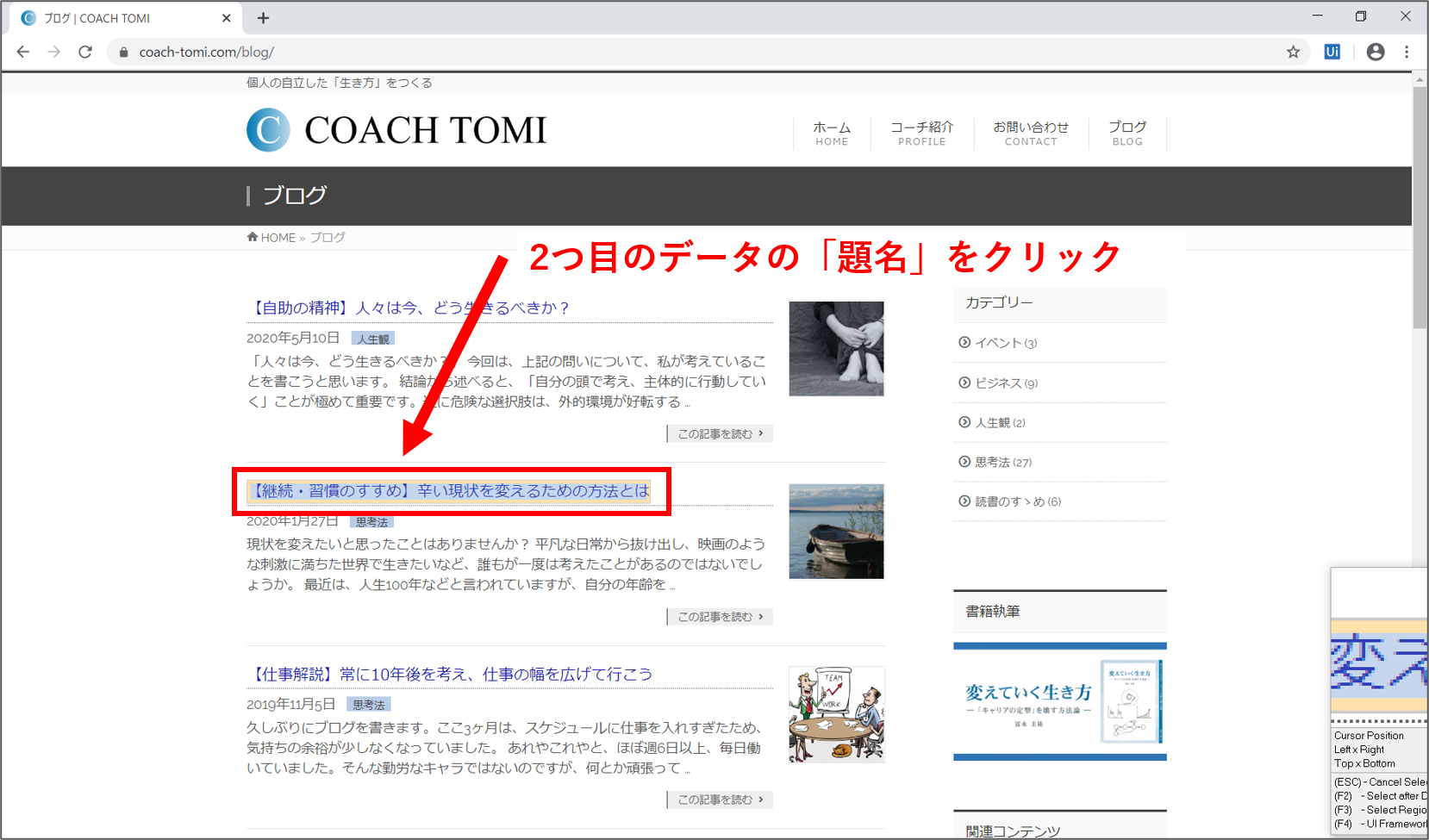
正しく指定できれば、「Configure Columns」の設定画面が開きます。ここで、「Extract URL」をチェックすることで、リンクのURLも同時に取得してくれます。項目名(題名およびURL)を入力して、「Next」ボタンをクリックします。
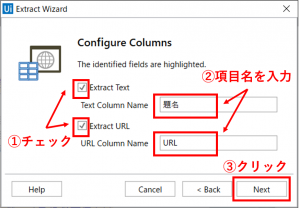
「Preview Data」の設定画面が開きますので、「Finish」ボタンをクリックします。
【Step.9】複数ページの設定
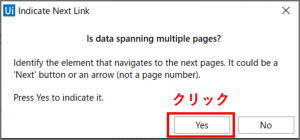
「Indicate Next Link」の設定画面が開きます。データが複数ページにまたがる場合は、自動でページ送りするように設定する必要があります。(複数ページにまたがらない場合は、「No」ボタンをクリックします)
事前に画面を一番下までスクロールして、ページ送りするリンクボタンを表示させます。この状態で、「Indicate Next Link」の設定画面の「Yes」ボタンをクリックします。
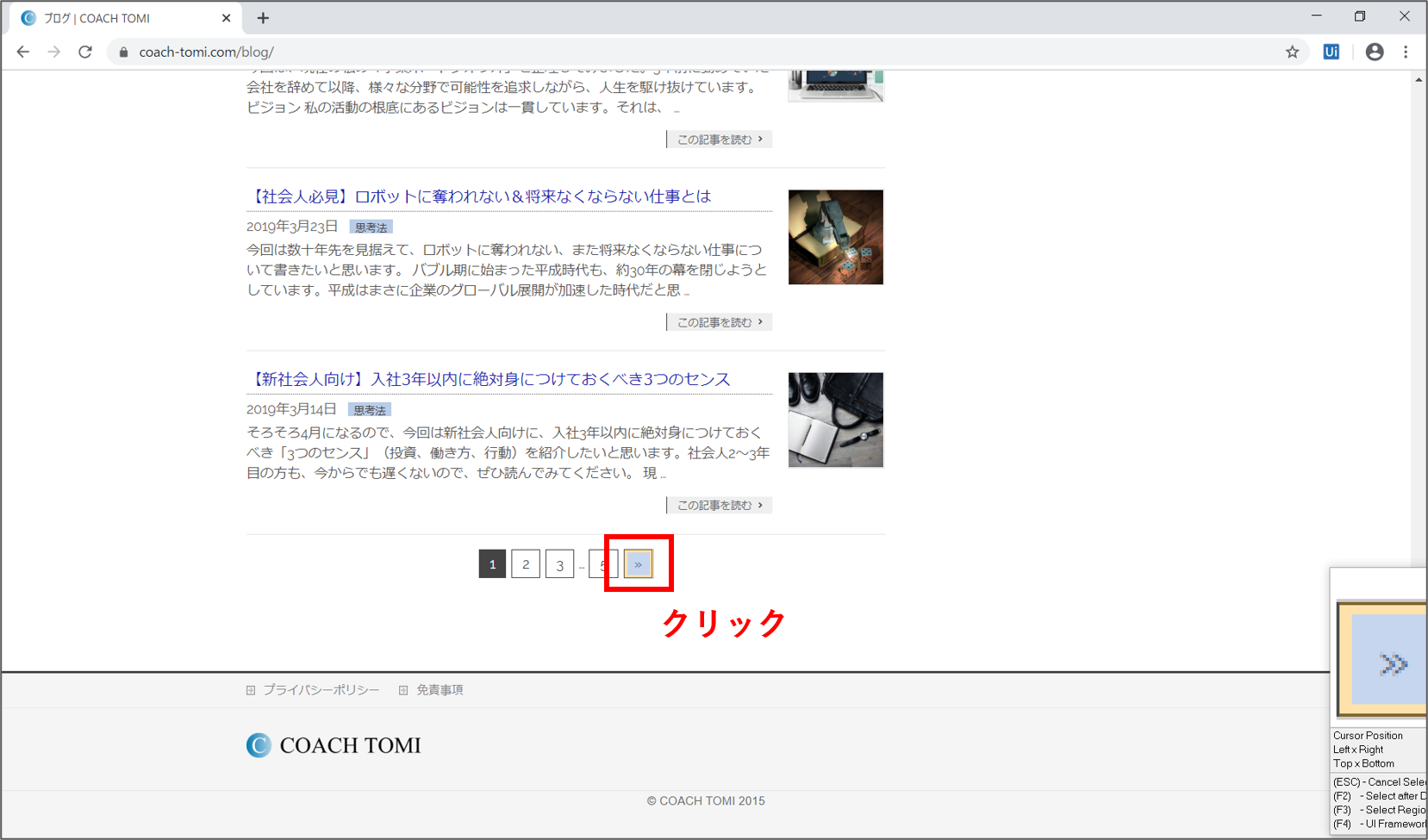
そして、次のページに遷移するリンク(「次へ」、「Next」、「>>」など)をクリックします。これでページ送りの設定は完了です。
【Step.10】Webレコーディングの終了
「Web Recording」パネルが表示されていると思うので、「Close Browser」を選択します。
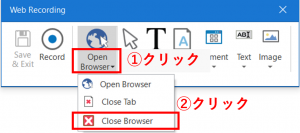
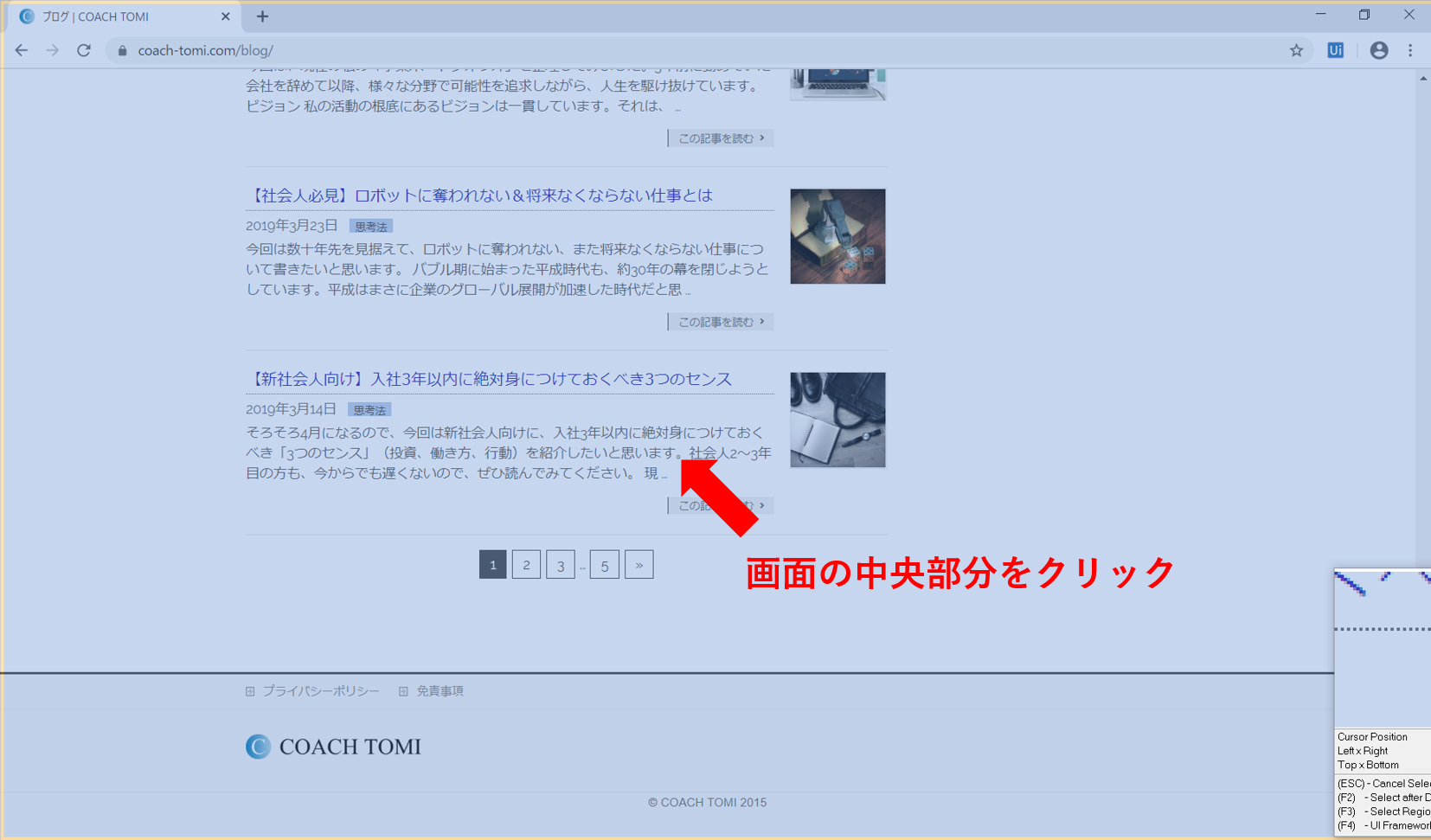
開いているWebブラウザの中央部分にカーソル(黄色の枠)を合わせます。この状態でクリックを押します。
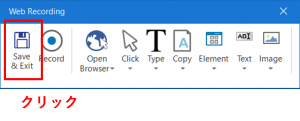
これで、Webブラウザが閉じると思います。最後は、「Web Recording」パネルの「Save & Exit」を押して、今まで記録してきたワークフローを出力します。
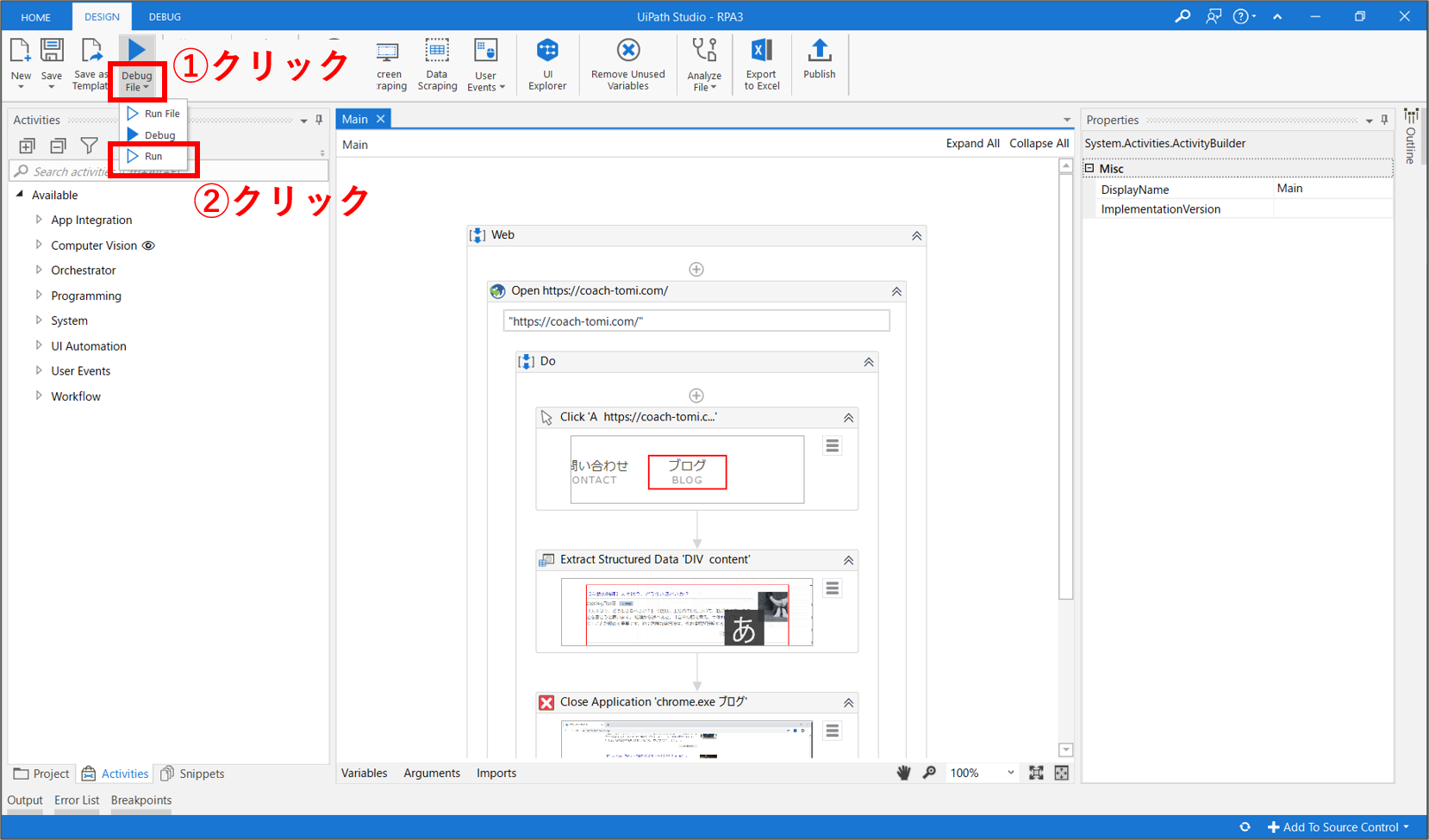
【Step.11】ワークフローの実行
UiPathの画面中央にWebレコーディングで自動記録されたワークフローが表示されていると思います。上部パネルの「Debug File > Run」をクリックし、このワークフローを実行してみましょう。
如何でしょうか。Webブラウザが起動して、ブログ記事の一覧画面をページ送りしていったと思います。ただし、このままでは、取得したデータを何にも使わずに処理が終わります。
そこで、処理の最後に、取得したデータをCSVファイルに出力してみたいと思います。そのためには、作成されたワークフローを一部編集する必要があります。
UiPathのワークフロー編集
【Step.12】ワークフローの観察
編集する前にワークフロー全体を少し観察してみましょう。ワークフローは最小単位「アクティビティ」から構成されています。今回登場する主要なアクティビティを下表に簡単に纏めます。なお、画面右側のプロパティ欄で、各アクティビティの詳細な設定ができます。
| アクティビティ名 | 解説 |
|---|---|
| Open Browser | Webブラウザを起動します。主要パラメータはWebサイトのURL(Url)です。プロパティの「Hidden」をONにすると、Webブラウザを非表示の状態で実行できる場合があります。 |
| Click | Webサイトのボタンやリンクをクリックします。 |
| Extract Structured Data | Webサイトに表示された構造データ(テーブルデータや繰り返しデータ)を取得します。取得した構造データはプロパティの「DataTable」に設定した変数に保存されます。 |
| Close Application | 各種アプリケーションを閉じます。 |
【Step.13】変数名の変更
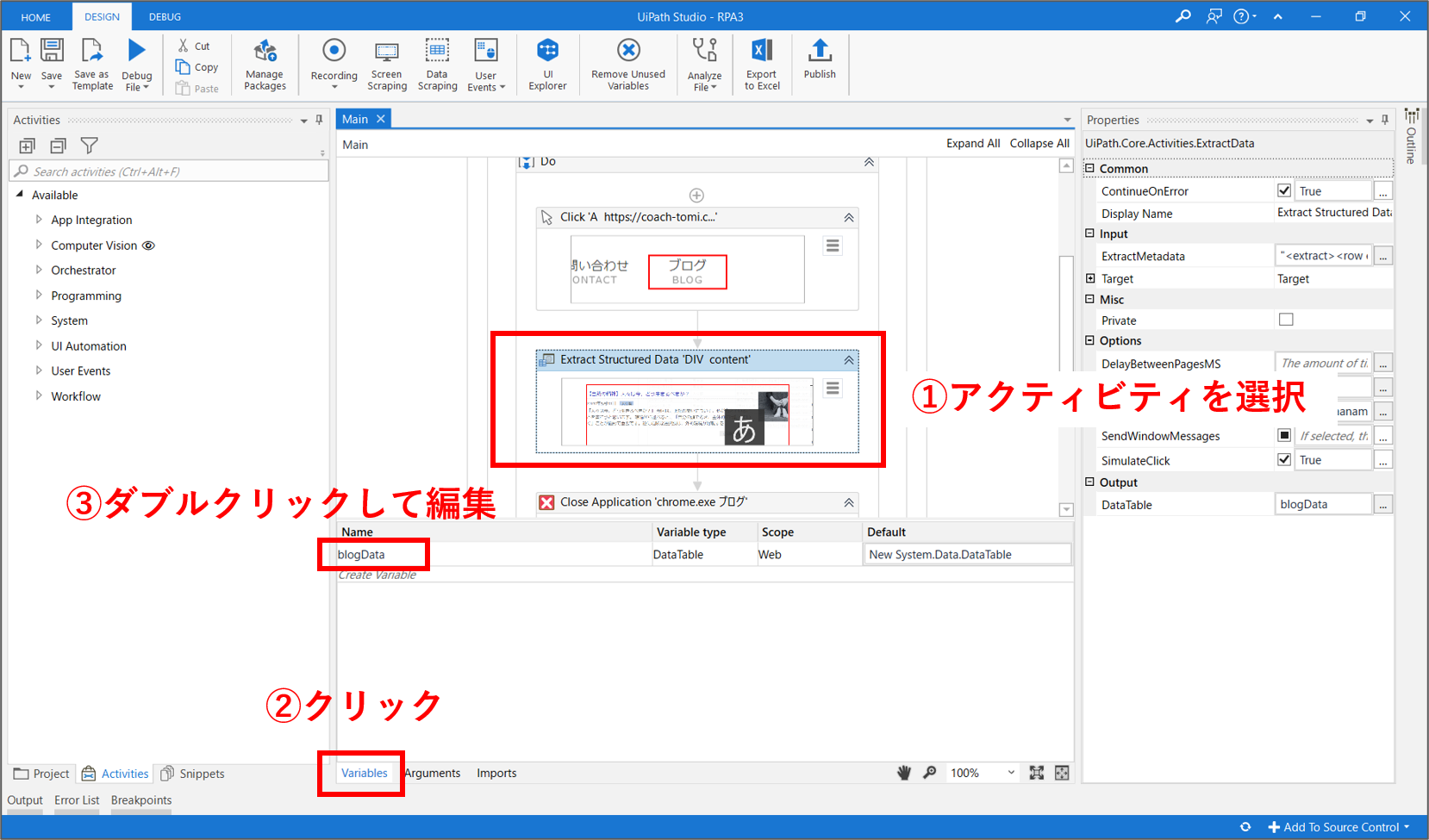
ワークフロー内の、「Extract Structured Data」アクティビティを選択します。画面下側の「Variables」タブをクリックして、既に定義した変数の名称や型を編集します。この変数管理画面で編集すると、ワークフロー全体に変更が反映されます。
Webレコーディングで、「Scrape Data」機能を使用した場合は、自動で変数が作成されます。基本的に、変数名はその中身を推測できる名称をつけるべきです。変数名をダブルクリックして、「blogData」に変更します。
【Step.14】「Write CSV」アクティビティを追加
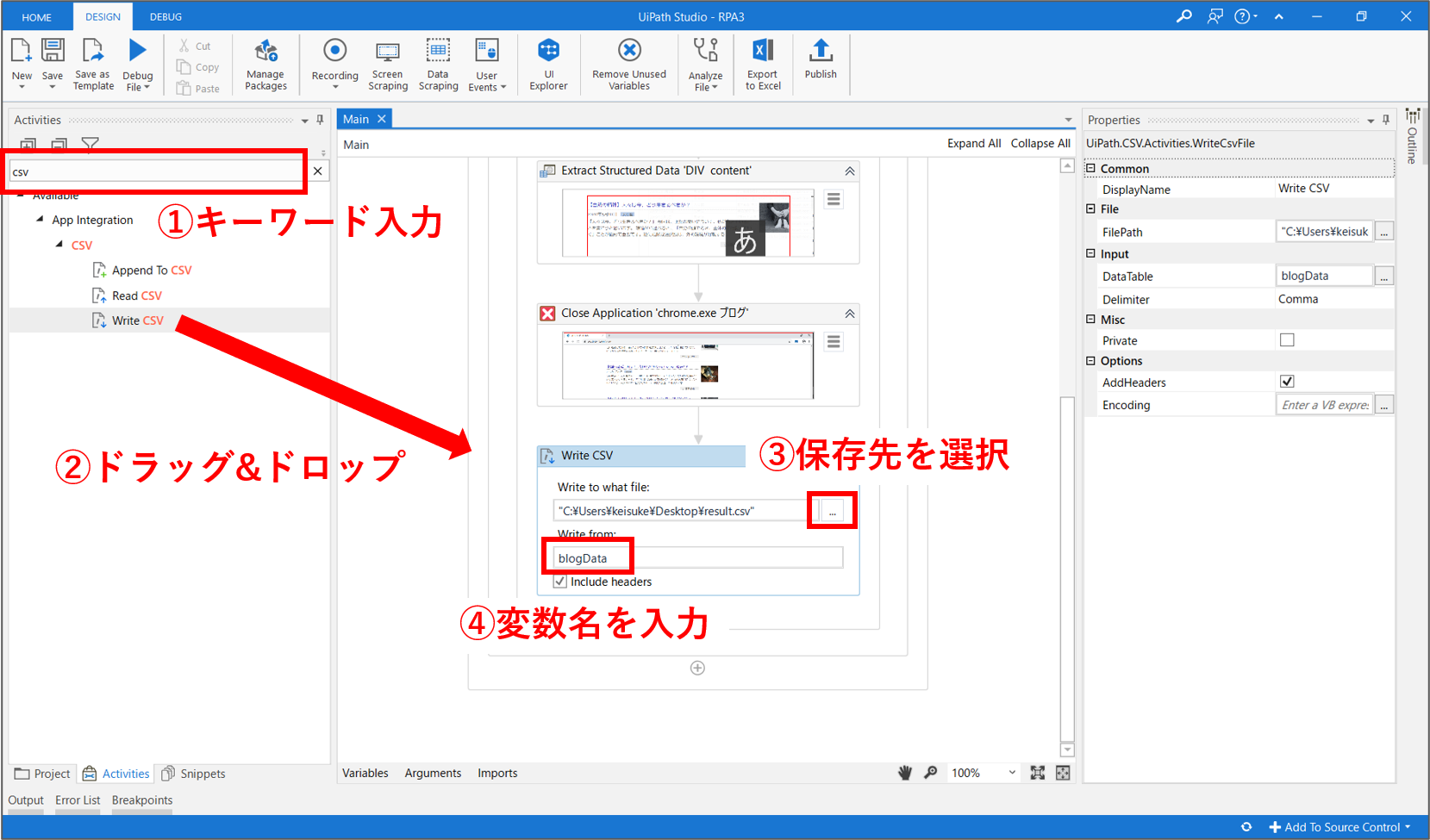
ワークフローの最後に、CSVファイルに取得したデータを出力する処理を追加します。先ずは、画面左側のアクティビティ検索窓に「csv」と入力します。表示された「Write CSV」アクティビティを、ワークフロー内の「Close Application」の直下にドラッグ&ドロップします。
「Write CSV」アクティビティの2つの入力欄の設定を行います。先ずは、保存先のファイルパス(ファイル名はresult.csv)を指定します。次に、DataTableの値に「blogData」と入力します。変数「blogData」には、「Extract Structured Data」アクティビティで取得したデータが保存されています。これで、準備が完了しました。
【Step.15】ワークフローの再実行
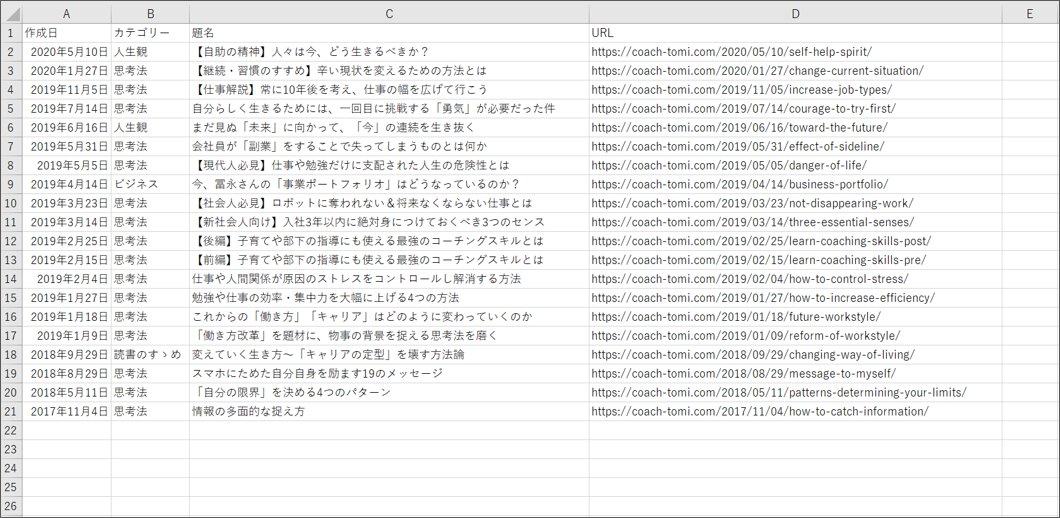
では、再び、上部パネルの「Debug File > Run」をクリックし、このワークフローを実行してみましょう。今度は、取得したデータのCSVファイルが、指定した保存場所に作成されました。上手く、Webサイトからブログ記事の見出し情報を取得することができています。
まとめ
今回は、Webサイトからブログ記事の見出し情報(繰り返しデータ)を取得して、CSVファイルに出力する処理を自動化しました。下記の点を理解して、他の業務にも応用できるようにしましょう。
- Webレコーディングを使用した自動記録
- 「Scrape Data」によるWebサイトの繰り返しデータ取得
- 「Write CSV」によるCSVファイル出力
関連記事
 2023年12月16日 RPA追加トレーニング(Lv.2 中級)
2023年12月16日 RPA追加トレーニング(Lv.2 中級) 2022年2月5日 【時系列マップ解説】過去に実践してきたプログラミング言語の具体的な勉強方法と順番
2022年2月5日 【時系列マップ解説】過去に実践してきたプログラミング言語の具体的な勉強方法と順番 2021年6月12日 【事例No.6】Power Automate Desktop講座の学習教材制作
2021年6月12日 【事例No.6】Power Automate Desktop講座の学習教材制作 2020年11月12日 【事例No.3】Chatworkへの領収書ファイルの自動アップロード
2020年11月12日 【事例No.3】Chatworkへの領収書ファイルの自動アップロード